概念:什么是分支预测?
在电脑架构中,分支预测器(英语:Branch predictor)是一种数字电路,在分支指令执行结束之前猜测哪一路分支将会被运行,以提高处理器的指令流水线的性能。使用分支预测器的目的,在于改善指令管线化的流程。现代使用指令管线化处理器的性能能够提高,分支预测器对于现今的指令流水线微处理器获得高性能是非常关键的技术。
如果没有分支预测器,处理器将会等待分支指令通过了指令流水线的执行阶段,才把下一条指令送入流水线的第一个阶段—取指令阶段(fetch stage)。这种技术叫做流水线停顿(stream stalled)或者流水线冒泡(stream bubbling)或者分支延迟间隙。这是早期的RISC体系结构处理器采用的应对分支指令的流水线执行的办法。
分支预测器猜测两路分支中哪一路最可能发生,然后投机执行这一路的指令,来避免流水线停顿造成的时间浪费。如果后来发现分支预测错误,那么流水线中投机执行的那些中间结果全部放弃,重新取得正确的分支路线上的指令开始执行,这招致了程序执行的延迟。
在分支预测失败时浪费的时间是从取指令到执行完指令(但还没有写回结果)的流水线的级数。现代微处理器趋向采用非常长的流水线,因此分支预测失败可能会损失10-20个时钟周期。越长的流水线就需要越好的分支预测。
参考维基百科:
http://zh.wikipedia.org/wiki/%E5%88%86%E6%94%AF%E9%A0%90%E6%B8%AC%E5%99%A8
http://en.wikipedia.org/wiki/Branch_predictor
原理:分支预测如何工作?
例子:
当使用下面这串代码执行时,一个不排序数组直接计算,一个排序后再计算,大家猜猜各自个计算时间?
import java.util.Arrays;
import java.util.Random;
public class Main
{
public static void main(String[] args)
{
// Generate data
int arraySize = 32768;
int data[] = new int[arraySize];
Random rnd = new Random(0);
for (int c = 0; c < arraySize; ++c)
data[c] = rnd.nextInt() % 256;
// !!! With this, the next loop runs faster
// 排序数组,当不排序时注释掉
Arrays.sort(data);
// Test
long start = System.nanoTime();
long sum = 0;
for (int i = 0; i < 100000; ++i)
{
// Primary loop
for (int c = 0; c < arraySize; ++c)
{
if (data[c] >= 128)
sum += data[c];
}
}
System.out.println((System.nanoTime() - start) / 1000000000.0);
System.out.println("sum = " + sum);
}
}
WHY
看了执行时间后,大家会不会感到诧异?如果没有的话,你就不用往下看了,因为你知道的太多了。:smile:
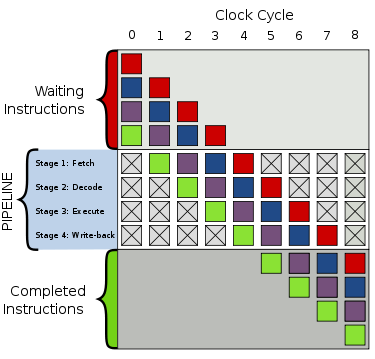
好,现在我们来解释一下,看下图:
假设你是个处理器,当你看到分支时,你不知道应该走向哪边。然后将执行挂起,直到前面所有的指令完成。然后继续执行正确的路径。
Modern processors are complicated and have long pipelines. So they take forever to “warm up” and “slow down”.
这儿有更好的方式嘛?当然有。这就是我们要讲的分支预测。
- 如果预测正确了,继续执行
- 如果预测错误了,需要刷新管道然后回滚分支,然后重试其他的分支。
所以,如果猜对了的话,执行将永远不会停止。
如果经常猜错,你将花费大量的时间停止,回滚,和重启。
这就是分支预测。
继续解释上面的程序:
T = branch taken
N = branch not taken
排序时:
data[] = 0, 1, 2, 3, 4, ... 126, 127, 128, 129, 130, ... 250, 251, 252, ...
branch = N N N N N ... N N T T T ... T T T ...
= NNNNNNNNNNNN ... NNNNNNNTTTTTTTTT ... TTTTTTTTTT (easy to predict)
未排序时:
data[] = 226, 185, 125, 158, 198, 144, 217, 79, 202, 118, 14, 150, 177, 182, 133, ...
branch = T, T, N, T, T, T, T, N, T, N, N, T, T, T, N ...
= TTNTTTTNTNNTTTN ... (completely random - hard to predict)
所以,你懂的,我就不说了。
题外话
那么除了分支预测,我想让这个程序跑的更快点,还有没有其他的方式。
这是世界上有许多hacker,他们就喜欢玩这样的。我们看看他们是怎么做到的。
代替:
if (data[c] >= 128)
sum += data[c];
用:
int t = (data[c] - 128) >> 31;
sum += ~t & data[c];
这里使用比特位操作来代替分支预测。
Benchmarks: Core i7 920 @ 3.5 GHz
Java - Netbeans 7.1.1 JDK 7 - x64
// Branch - Random
seconds = 10.93293813
// Branch - Sorted
seconds = 5.643797077
// Branchless - Random
seconds = 3.113581453
// Branchless - Sorted
seconds = 3.186068823
- With the Branch: There is a huge difference between the sorted and unsorted data.
- With the Hack: There is no difference between sorted and unsorted data.
A general rule of thumb is to avoid data-dependent branching in critical loops.
在条件循环中要避免依赖数据的分支。(:grin:高级黑呀)
分支预测的实现
静态预测
总是预测条件跳转不发生,因此总是顺序取下一条指令投机执行。
仅当条件跳转指令被求值确实发生了跳转,则非顺序的代码地址被加载执行。
饱和计数
饱和计数器(saturating counter)或者称双模态预测器(bimodal predictor)是一种有4个状态的状态机:
- 强不选择(Strongly not taken)
- 弱不选择(Weakly not taken)
- 弱选择(Weakly taken)
- 强选择(Strongly taken)
当一个分支命令被求值,对应的状态机被修改。分支不采纳,则向“强不选择”方向降低状态值;如果分支被采纳,则向“强选择”方向提高状态值。这种方法的优点是,该条件分支指令必须连续选择某条分支两次,才能从强状态翻转,从而改变了预测的分支。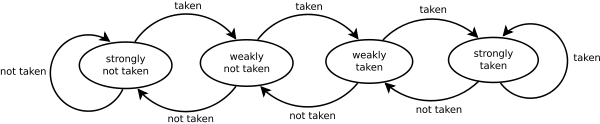
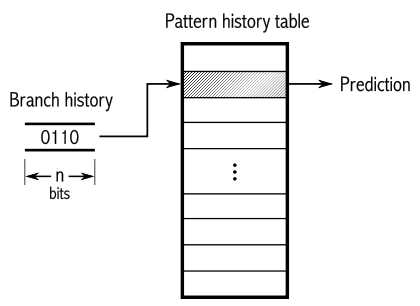
两级自适应预测器
对于一条分支指令,如果每2次执行发生一次条件跳转,或者其它的规则发生模式,那么用上文提到的饱和计数器就很难预测了。如图所示,一种二级自适应预测器可以记住过去n次执行该指令时的分支情况的历史,可能的2n种历史模式的每一种都有1个专用的饱和计数器,用来表示如果刚刚过去的n次执行历史是此种情况,那么根据这个饱和计数器应该预测为跳转还是不跳转。
例如,n = 2。这意味着过去的2次分支情况被保存在一个2位的移位寄存器中。因此可能有4种不同的分支历史情况:00, 01, 10, 11。其中0表示未发生跳转,1表示发生了分支跳转。现在,设计一个模式历史表(pattern history table),有4个条目,对应于2n = 4种可能的分支历史情况。4种历史情况的每一种都在模式历史表对应于一个2位饱和计数器。分支历史寄存器用于选择哪个饱和计数器供现在使用。如果分支历史寄存器是00,那么选择第一个饱和计数器;如果分支历史寄存器是11,那么选择第4个饱和计数器。
假定,例如条件跳转每隔2次执行就发生一次,即分支情况的历史串行是001001001…。在这种情况下,00对应的饱和计数器将是状态“强选择”(strongly taken),表明在两个0之后必然是出现一个1。01对应的饱和计数器将是状态“强不选择”(strongly not taken),表示在01之后必然是出现一个0。这也同样适用于10状态。而11状态从未使用,因为不可能出现连续两个1。
2级自适应预测器的一般规则是n位分支历史寄存器,可以预测在所有n周期以内出现的所有的重复串行的模式。[2]
2级自适应预测器的优点是能快速学会预测任意的重复模式。此方法1991年被提出。[5] 已经变得非常流行。以此为基础很多变种方法被用于现代微处理器。