粒度问题
由于以前生成的方法仅仅能够在规则上产生,当我们想要更小的粒度时,针对每个规则进行更小的粒度控制时,我们就显得力不从心了。
这样,就产生了lable…
无标签情况下
下面是一个计算器。
grammar Expr;
s : e ;
e : e op=MULT e // MULT is '*'
| e op=ADD e // ADD is '+'
| INT
;
MULT: '*' ;
ADD : '+' ;
INT : [0-9]+ ;
WS : [ \t\n]+ -> skip ;
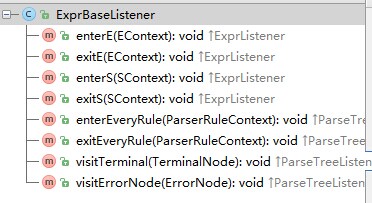
public static class Evaluator extends ExprBaseListener {
Stack<Integer> stack = new Stack<Integer>();
public void exitE(ExprParser.EContext ctx) {
if ( ctx.getChildCount()==3 ) { // operations have 3 children
int right = stack.pop();
int left = stack.pop();
if ( ctx.op.getType()==ExprParser.MULT ) {
stack.push( left * right );
}
else {
stack.push( left + right ); // must be add
}
}
}
public void visitTerminal(TerminalNode node) {
Token symbol = node.getSymbol();
if ( symbol.getType()==ExprParser.INT ) {
stack.push( Integer.valueOf(symbol.getText()) );
}
}
}
从上面看出,原始的方式下,我们不得不对所有的操作符进行判断,即op=MULT和op=Add。
有标签情况下
grammar LExpr;
s : e ;
e : e MULT e # Mult
| e ADD e # Add
| INT # Int
;
MULT: '*' ;
ADD : '+' ;
INT : [0-9]+ ;
WS : [ \t\n]+ -> skip ;
注意不同点,我们使用#号来表示标签。这样,antlr就会对每个标签生成一个方法和特定的上下文对象。