前面几节我们介绍了一下mondrian最基础的东西,只有在了解了这些后,我们才能继续往下看。
首先,mondrian需要将mdx语句解析成java对象,我们先看看他是如何解析的。
Query创建过程
我们从ConnectionBase的parser开始,在parseStatement中,有一句很重要的话语句。
public Query parseQuery(String query) {
return (Query) parseStatement(query);
}
Query parseStatement(...){
...
return parser.parseInternal(
statement, query, debug, funTable, strictValidation);
...
}
一,创建解析器
首先,我们需要一个parser。在ConnectionBase类中,我们看到了parser的创建过程:
protected MdxParserValidator createParser() {
return true
? new JavaccParserValidatorImpl()
: new MdxParserValidatorImpl();
}
实际上,由于这里永远是true,所以返回的是JavaccParserValidatorImpl。这个类也是实现了MdxParserValidator。它与原生的javaccparser生成的MdxParserValidatorImpl的主要不同在于factory的创建方式和异常的处理方式,这里就不做过多解读了,具体请看源代码。
二,解析mdx
获取Parser后,通过调用parser的parseInternal方法,获取到一个QueryPart。这是如何解析的呢?在mondrian/parser目录下,有个MdxParser.jj的文件。这个文件是用javacc的语法来写的,如果不懂javacc的语法,可以移步到网上看看:http://java.net/projects/javacc/,这里就不展开了。
QueryPart parseInternal(
Statement statement,
String queryString,
boolean debug,
FunTable funTable,
boolean strictValidation);
QueryPart类
QueryPart是什么呢?我们看下图,他的主要功能是获取子节点。于是我们知道,任何具有子节点的对象都可以是一个QueryPart,右边框框中框出来所有的继承关系。
在parseInternal中产生的是那个对象什么呢?通过DEBUG代码后,我们可以看到是Query对象,即mdx语句被转换成了Query。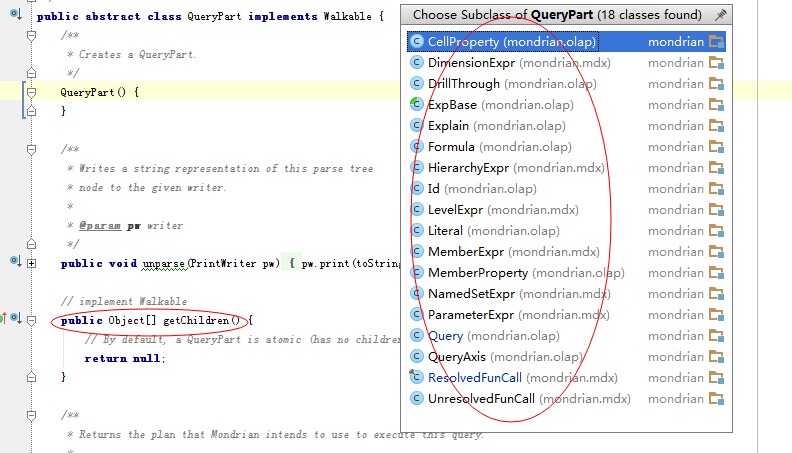
Query初始化
我们先看看他的构造方法:
/**
* Creates a Query.
*/
public Query(
Statement statement,
Cube mdxCube,
Formula[] formulas,
QueryAxis[] axes,
QueryAxis slicerAxis,
QueryPart[] cellProps,
Parameter[] parameters,
boolean strictValidation)
{
this.statement = statement;
this.cube = mdxCube;
this.formulas = formulas;
this.axes = axes;
normalizeAxes();
this.slicerAxis = slicerAxis;
this.cellProps = cellProps;
this.parameters.addAll(Arrays.asList(parameters));
this.measuresMembers = new HashSet<Member>();
// assume, for now, that cross joins on virtual cubes can be
// processed natively; as we parse the query, we'll know otherwise
this.nativeCrossJoinVirtualCube = true;
this.strictValidation = strictValidation;
this.alertedNonNativeFunDefs = new HashSet<FunDef>();
statement.setQuery(this);
resolve();
if (RolapUtil.PROFILE_LOGGER.isDebugEnabled()
&& statement.getProfileHandler() == null)
{
statement.enableProfiling(
new ProfileHandler() {
public void explain(String plan, QueryTiming timing) {
if (timing != null) {
plan += "\n" + timing;
}
RolapUtil.PROFILE_LOGGER.debug(plan);
}
}
);
}
}
resolve
在上面中,我们着重看resolve方法。
这个是完成Query功能最重要的地方,在这里,query完成了它自己的构建,包括类型检测,UnresolvedFunCall对象到ResolvedFunCall对象的转化,添加测量成员,创建查询轴计算器,切片轴计算器等。
- 创建校验器
- 解析自己和子节点
- 创建编译器
- 编译
public void resolve() {
final Validator validator = createValidator(); // 1
resolve(validator); // 2 resolve self and children
// Create a dummy result so we can use its evaluator
final Evaluator evaluator = RolapUtil.createEvaluator(statement);
ExpCompiler compiler =
createCompiler(
evaluator, validator, Collections.singletonList(resultStyle));//3
compile(compiler);//4
}
resolve(validator)
我们看第2步,解析自己和子节点,这一步最重要的就是将UnresolvedFunCall对象转化为ResolvedFunCall对象
- 首先构建formulas的内部成员,具体请看
formula.createElement(validator.getQuery());方法,这里就不展开了。 - 注册参数
- 注册别名表达式
- 校验formulas,主要是将formula中的id解析成表达式对象
- 校验查询轴和切片轴,在此过程中会获取查询轴计算器和切片轴计算器
- 校验一个层次只能存在一个轴上
/**
* Performs type-checking and validates internal consistency of a query.
*
* @param validator Validator
*/
public void resolve(Validator validator) {
// Before commencing validation, create all calculated members,
// calculated sets, and parameters.
if (formulas != null) {
// Resolving of formulas should be done in two parts
// because formulas might depend on each other, so all calculated
// mdx elements have to be defined during resolve.
for (Formula formula : formulas) {
formula.createElement(validator.getQuery());
}
}
// Register all parameters.
parameters.clear();
parametersByName.clear();
accept(new ParameterFinder());
// Register all aliased expressions ('expr AS alias') as named sets.
accept(new AliasedExpressionFinder());
// Validate formulas.
if (formulas != null) {
for (Formula formula : formulas) {
validator.validate(formula);
}
}
// Validate axes.
if (axes != null) {
Set<Integer> axisNames = new HashSet<Integer>();
for (QueryAxis axis : axes) {
validator.validate(axis);
if (!axisNames.add(axis.getAxisOrdinal().logicalOrdinal())) {
throw MondrianResource.instance().DuplicateAxis.ex(
axis.getAxisName());
}
}
// Make sure that there are no gaps. If there are N axes, then axes
// 0 .. N-1 should exist.
int seekOrdinal =
AxisOrdinal.StandardAxisOrdinal.COLUMNS.logicalOrdinal();
for (QueryAxis axis : axes) {
if (!axisNames.contains(seekOrdinal)) {
AxisOrdinal axisName =
AxisOrdinal.StandardAxisOrdinal.forLogicalOrdinal(
seekOrdinal);
throw MondrianResource.instance().NonContiguousAxis.ex(
seekOrdinal,
axisName.name());
}
++seekOrdinal;
}
}
if (slicerAxis != null) {
slicerAxis.validate(validator);
}
// Make sure that no hierarchy is used on more than one axis.
for (Hierarchy hierarchy : ((RolapCube) getCube()).getHierarchies()) {
int useCount = 0;
for (QueryAxis axis : allAxes()) {
if (axis.getSet().getType().usesHierarchy(hierarchy, true)) {
++useCount;
}
}
if (useCount > 1) {
throw MondrianResource.instance().HierarchyInIndependentAxes.ex(
hierarchy.getUniqueName());
}
}
}
compile(compiler)
然后我们看第4步,这步主要是创建查询轴计算器,切片轴计算器等。
/**
* Generates compiled forms of all expressions.
*
* @param compiler Compiler
*/
private void compile(ExpCompiler compiler) {
if (formulas != null) {
for (Formula formula : formulas) {
formula.compile();
}
}
if (axes != null) {
axisCalcs = new Calc[axes.length];
for (int i = 0; i < axes.length; i++) {
axisCalcs[i] = axes[i].compile(compiler, resultStyle);
}
}
if (slicerAxis != null) {
slicerCalc = slicerAxis.compile(compiler, resultStyle);
}
}