一,概述
本文主要介绍java序列化方面的一些基础知识。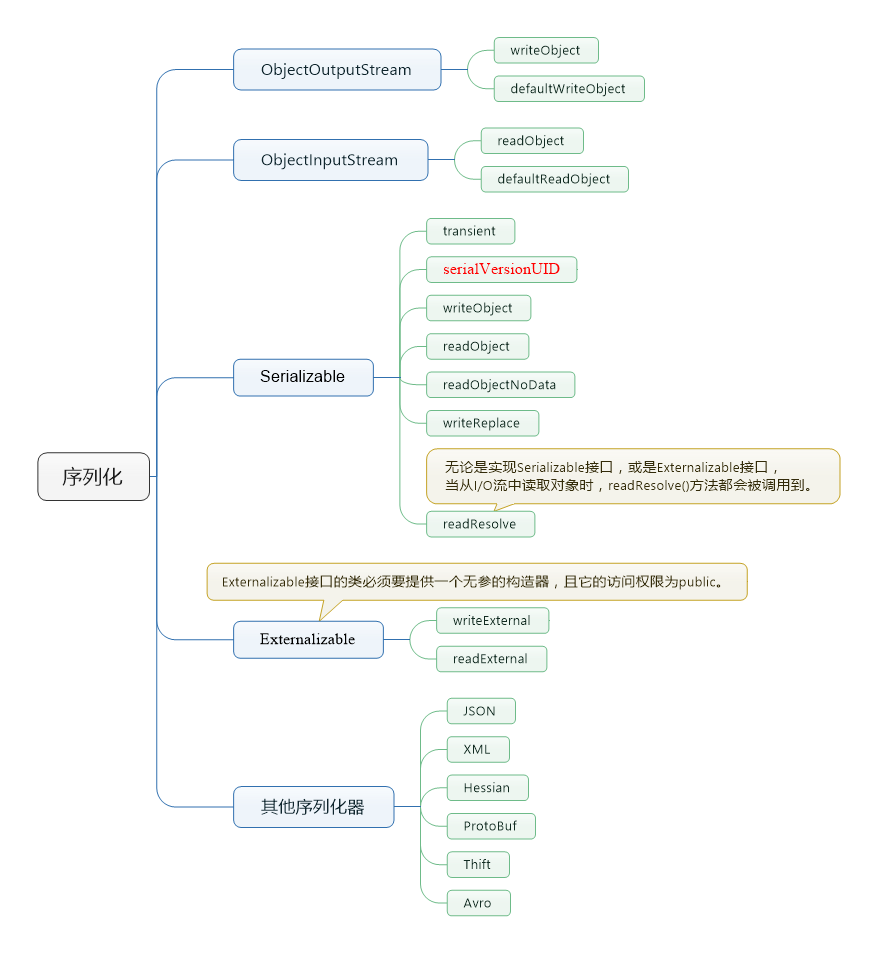
二,java序列化类介绍
1,Serializable接口
1.1.triansant
当某个字段被声明为transient后,默认序列化机制就会忽略该字段。
1.2.serialVersionUID
序列化版本号,用来保证两个类是否是兼容的。默认情况下应该给一个值,不然系统会在运行的时候调用一个复杂的过程来生成这个值。
1.3writeObject和readObject
通过实现这2个方法来生成自己的自定义序列化方式。
1.4readObjectNoData
当没有获取到对象数据时,默认的初始化行为。
1.5writeReplace和readResolve
控制实例化对象的写入写出,可以指定任意对象。可通过此接口来禁止单例对象的多态化。
2,ObjectOutputStream和ObjectInputStream
实际的序列化和反序列化工作是通过ObjectOuputStream和ObjectInputStream来完成的。
ObjectInputStream:
- readObject : 从流中读取一个Java对象
- defaultWriteObject:默认的写入方法,注意这不是说默认会调用,而是采用默认的算法。
ObjectOutputStream:
- writeObject:把一个Java对象写入到流中
- defaultReadObject: 默认的读取算法。
3,Externalizable接口
无论是使用transient关键字,还是使用writeObject()和readObject()方法,其实都是基于Serializable接口的序列化。JDK中提供了另一个序列化接口—Externalizable,使用该接口之后,之前基于Serializable接口的序列化机制就将失效。
- writeExternal:把一个Java对象写入到流中
- readExternal:从流中读取一个Java对象
三,其他序列化器
1,json
json的序列化框架有fastjson,jackson,gson等。
适用性:
- 公司之间传输数据量相对小,实时性要求相对低(例如秒级别)的服务。
- 基于Web browser的Ajax请求。
- 由于JSON具有非常强的前后兼容性,对于接口经常发生变化,并对可调式性要求高的场景,例如Mobile app与服务端的通讯。
2,xml
xml的序列化框架有XStream。
XML的序列化和反序列化的空间和时间开销都比较大,对于对性能要求在ms级别的服务,不推荐使用。
3,hessian
hessian主要用于java序列化。它的实现机制是着重于数据,附带简单的类型信息的方法:
- 对于简单的数据类型。就像Integer a = 1,hessian会序列化成I 1这样的流,I表示int or Integer,1就是数据内容。
- 对于复杂对象,通过Java的反射机制,hessian把对象所有的属性当成一个Map来序列化,产生类似M className propertyName1 I 1 propertyName S stringValue
- 对于引用对象,在序列化过程中,如果一个对象之前出现过,hessian会直接插入一个R index这样的块来表示一个引用位置,从而省去再次序列化和反序列化的时间。
4,thift
Thrift是Facebook开源提供的一个高性能,轻量级RPC服务框架,其产生正是为了满足当前大数据量、分布式、跨语言、跨平台数据通讯的需求。 但是,Thrift并不仅仅是序列化协议,而是一个RPC框架。相对于JSON和XML而言,Thrift在空间开销和解析性能上有了比较大的提升,对于对性能要求比较高的分布式系统,它是一个优秀的RPC解决方案;但是由于Thrift的序列化被嵌入到Thrift框架里面,Thrift框架本身并没有透出序列化和反序列化接口,这导致其很难和其他传输层协议共同使用(例如HTTP)。
5,protobuf
- 序列化数据非常简洁,紧凑.
- 解析速度非常快
- 提供了非常友好的动态库,使用非常简介,反序列化只需要一行代码。
6,avro
Avro的产生解决了JSON的冗长和没有IDL的问题。 Avro提供两种序列化格式:JSON格式或者Binary格式。Binary格式在空间开销和解析性能方面可以和Protobuf媲美,JSON格式方便测试阶段的调试。
- 动态类型:Avro并不需要生成代码,模式和数据存放在一起,而模式使得整个数据的处理过程并不生成代码、静态数据类型等等。这方便了数据处理系统和语言的构造。
- 未标记的数据:由于读取数据的时候模式是已知的,那么需要和数据一起编码的类型信息就很少了,这样序列化的规模也就小了。
- 不需要用户指定字段号:即使模式改变,处理数据时新旧模式都是已知的,所以通过使用字段名称可以解决差异问题。
四,参考资料
- 序列化的秘密.pdf —-liujia
- jvm-serializers
- 序列化和反序列化
- Java对象序列化与RMI
- Google Protocol Buffer 的使用和原理
- Avro:大数据的二进制传输中间件