一,概述
twitter的一位工程师说过一句话,“Biggest threat to responsiveness in the JVM is the garbage collector”,可见垃圾收集器的重要性。下面,我将总结一下GC调优的方方面面,希望以后在这里能少走弯路。
二,监控命令
1,jdk命令
1.1 jps 进程状态信息
jps [options] [hostid]
-q 不输出类名、Jar名和传入main方法的参数
-m 输出传入main方法的参数
-l 输出main类或Jar的全限名
-v 输出传入JVM的参数
1.2 jstack 线程堆栈信息
jstack [option] pid
-l long listings,会打印出额外的锁信息,在发生死锁时可以用jstack -l pid来观察锁持有情况
-m mixed mode,不仅会输出Java堆栈信息,还会输出C/C++堆栈信息(比如Native方法)
1.3 jmap 堆内存使用状况
jmap [option] pid
jmap -permstat pid
打印进程的类加载器和类加载器加载的持久代对象信息,输出:类加载器名称、对象是否存活(不可靠)、对象地址、父类加载器、已加载的类大小等信息
jmap -heap pid
查看进程堆内存使用情况,包括使用的GC算法、堆配置参数和各代中堆内存使用情况。
jmap -histo[:live] pid
查看堆内存中的对象数目、大小统计直方图,如果带上live则只统计活对象 (注意:执行此语句会造成Full GC)
jmap -dump:format=b,file=dumpFile pid
1.4 jstat 统计监测工具
jstat [ generalOption | outputOptions vmid [interval[s|ms] [count]] ]
vmid是Java虚拟机ID,在Linux/Unix系统上一般就是进程ID。interval是采样时间间隔。count是采样数目。
root@ubuntu:/# jstat -gc 21711 250 4
S0C S1C S0U S1U EC EU OC OU PC PU YGC YGCT FGC FGCT GCT
192.0 192.0 64.0 0.0 6144.0 1854.9 32000.0 4111.6 55296.0 25472.7 702 0.431 3 0.218 0.649
192.0 192.0 64.0 0.0 6144.0 1972.2 32000.0 4111.6 55296.0 25472.7 702 0.431 3 0.218 0.649
192.0 192.0 64.0 0.0 6144.0 1972.2 32000.0 4111.6 55296.0 25472.7 702 0.431 3 0.218 0.649
192.0 192.0 64.0 0.0 6144.0 2109.7 32000.0 4111.6 55296.0 25472.7 702 0.431 3 0.218 0.649
S0C、S1C、S0U、S1U:Survivor 0/1区容量(Capacity)和使用量(Used)
EC、EU:Eden区容量和使用量
OC、OU:年老代容量和使用量
PC、PU:永久代容量和使用量
YGC、YGT:年轻代GC次数和GC耗时
FGC、FGCT:Full GC次数和Full GC耗时
GCT:GC总耗时
2, 系统命令
2.1 top
参数:
H Show all threads by process
1 显示各个CPU的运行情况
关键指标:
- us%
用户进程CPU使用(us)消耗:正常 65%-70%
过高,表示应用消耗了大部分的CPU。原因通常是大量计算或GC导致。 - sy%:
内核CPU使用(sy)消耗:正常 30%-35%
过高,表示OS花费了大量时间在进行线程切换. 原因通常是线程启动过多,并都处于不断阻塞状态或线程状态不断在变化。
top命令可以和jstack结合用
top -H –p javaid
查看某个进程的线程,找到最用cpu最高的线程后,
printf '0x%x\n' tid
转换线程id为16进制
jstack -l javaid | grep 16进制tid
2.2 vmstat
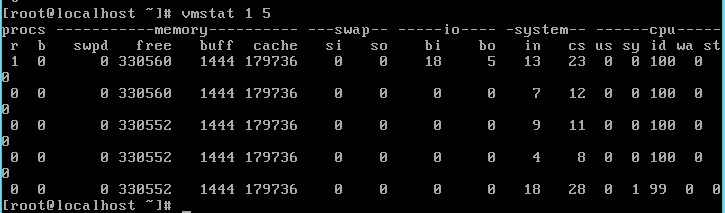
关键指标:
- r(等待和正在运行队列的进程数) 数大于CPU个数, 则有可能出现CPU瓶颈
- b(等待IO的进程数) 经常过高, 则io(网络IO/文件IO)消耗严重。
- 通过应当结合CPU利用率和CPU Load average来判断性能问题。
- 如果每个CPU的平均load值大于5(load/cpu count)则存在严重的性能问题(无论CPU利用率如何)。
2.3 iostat
查看各硬盘IO负载信息
确定 IO瓶颈重要指标在于 r/s、 w/s 及 rkB/s、 wkB/s,前者为 tps, 后者为吞吐量。
IO 操作对时间消耗可从 util% 看出,如将近100%表示 io 请求(tps)过多。
await 远远大于 svctm, 说明等待的系统IO处理的队列太长, 则会导致响应时间变慢。
2.4 pidstat
各进程/线程对CPU利用率
三,JDK配置参数
1,内存参数
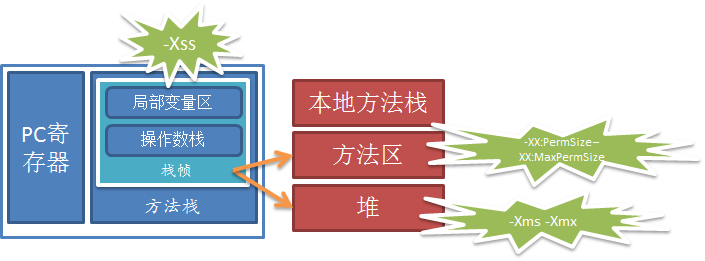
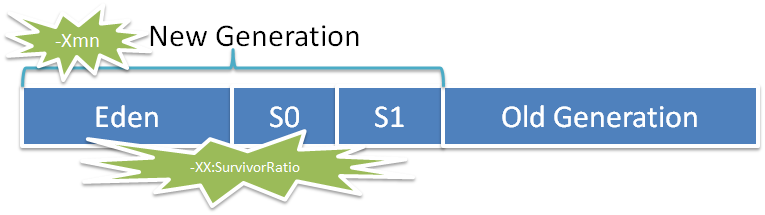
-Xms –Xmx -XX:PermSize -XX:MaxPermSize 最好设置成一样,防止“堆震荡”
-XX:SurvivorRatio :设置年轻代中Eden区与Survivor区的大小比值
2,日志参数
四,性能诊断
OOM
对象未释放
- 查看大对象
Full GC频繁
对象占用时间太长
- 查看大对象
CMS
promotion failed,concurrent mode failure
- 如为内存用完的情况,则dump内存分析;
- 如为cms gc碎片问题,暂时只能定时执行下jmap –histo:live;
StackOverFlow
打印线程栈
CPU高负荷
- 查看线程争用,上下文切换
- 查看线程死锁