一,前言
孔子说,温故而知新,可以为师矣。好久没探讨列式数据库了,今天在此再次总结一遍,供以后查阅。本文介绍的内容如下: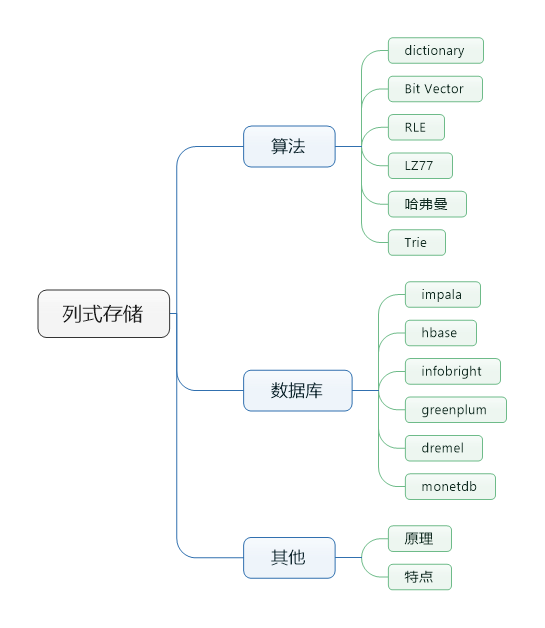
二,存储算法
对于一列值,你认为会有哪些存储方式呢?下面我们来看看常用的存储算法:
2.1 dictionary(字典项编码)
这个最常用的,不说了,so easy。
2.2 bit Vector(比特向量)
适用于重复度比较高的。
比如一列 ABAABCCCAABB
对于字段值A,B,C分别用一个bit Vector来存储他们的位置。
A 101100001100
B 010010000011
C 000001110000
2.3 RLE(Run-length encoding,行程编码)
RLE适合用于对已排序好的数据进行编码。
RLE由一下3部分组成:
控制符+重复次数+被重复字符
例如,字符串 RTAAAASDEEEEE
经RLE压缩后为: RT4ASD5E
在这里,”4A” 代替了流”AAAA”,”5E” 代替”EEEEE”。其中,控制符采用特殊字符’*’ 指出一个RLE编码的开始,后面的数字表示重复的次数,数字后的单个字符是被重复的字符。显然,重复字符数为4或大于4,RLE编码效率才高,因为一个重复至少需要3个符号来表示。
2.4 LZ算法簇
LZ算法簇包括LZ77,LZW,LZ78,LZSS,他们都是以LZ77算法为基础的,我们重点介绍LZ77算法。
我们先看个例子: the brown fox jumped over the brown foxy jumping frog
这个短语的长度总共是53个八位组 = 424 bit。算法从左向右处理这个文本。初始时,每个字符被映射成9 bit的编码,二进制的1跟着该字符的8 bit ASCII码。在处理进行时,算法查找重复的序列。当碰到一个重复时,算法继续扫描直到该重复序列终止。换句话说,每次出现一个重复时,算法包括尽可能多的字符。碰到的第一个这样的序列是the brown fox。这个序列被替换成指向前一个序列的指针和序列的长度。在这种情况下,前一个序列的the brown fox出现在26个字符之前,序列的长度是13个字符。对于这个例子,假定存在两种编码选项:8 bit的指针和4 bit的长度,或者12 bit的指针和6 bit的长度。使用2 bit的首部来指示选择了哪种选项,00表示第一种选项,01表示第二种选项。因此,the brown fox的第二次出现被编码为 <00b><26d><13 d="">,或者00 00011010 1101。
压缩报文的剩余部分是字母y;序列<00b><27d><5 d="">替换了由一个空格跟着jump组成的序列,以及字符序列ing frog。
下图演示了压缩映射的过程。压缩过的报文由35个9 bit字符和两个编码组成,总长度为35 x 9 + 2 x 14 = 343比特。和原来未压缩的长度为424比特的报文相比,压缩比为1.24。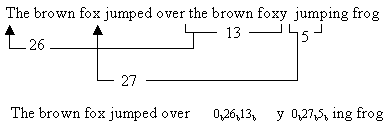
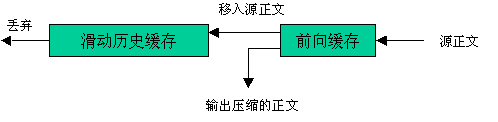
LZ77(及其变体)的压缩算法使用了两个缓存。滑动历史缓存包含了前面处理过的N个源字符,前向缓存包含了将要处理的下面L个字符。算法尝试将前向缓存开始的两个或多个字符与滑动历史缓存中的字符串相匹配。如果没有发现匹配,前向缓存的第一个字符作为9 bit的字符输出并且移入滑动窗口,滑动窗口中最久的字符被移出。如果找到匹配,算法继续扫描以找出最长的匹配。然后匹配字符串作为三元组输出(指示标记、指针和长度)。对于K个字符的字符串,滑动窗口中最久的K个字符被移出,并且被编码的K个字符被移入窗口。

2.5 哈弗曼编码
哈弗曼编码为前缀编码,即一个编码不是另一个编码的前缀。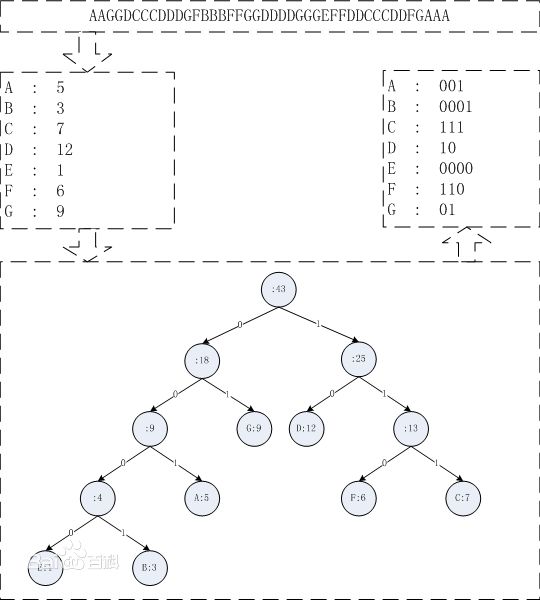
2.6 trie
Trie数据结构一般也叫prefix trees, 一般用在数据类型为string并且排序之后有明显倾斜的数据分布的列,比如URL , 家庭住址, 这些字段的前缀经过排序之后在局部区域往往都有很高的压缩比,在最近的Hbase 里面也使用了这种方式压缩rowKey 的部分,Google PowerDrill也同时使用Trie Encoding压缩由”字典表”和”字典表所在位置”所组成的文件格式及其对应的内存数据结构.
三,数据库
对于列式数据库都有哪些,他们都有哪些优缺点,下面我们将介绍一下。
3.1 impala
impala是基于hadoop大数据的列式数据库。impala主要使用的列式存储是parquet。
impala的性能快的原因:
- Impala不需要把中间结果写入磁盘,省掉了大量的I/O开销。
- 省掉了MapReduce作业启动的开销。
- Impala完全抛弃了MapReduce这个不太适合做SQL查询的范式,而是像Dremel一样借鉴了MPP并行数据库的思想另起炉灶,因此可做更多的查询优化,从而省掉不必要的shuffle、sort等开销。
- 用C++实现,做了很多有针对性的硬件优化,例如使用SSE指令。
- 使用了支持Data locality的I/O调度机制,尽可能地将数据和计算分配在同一台机器上进行,减少了网络开销。
3.2 hbase
hbase建立的hdfs之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统。
3.3 infobright
infobright是基于mysql的,它也是利用了MPP分布式架构。
infobright相比其他的数据库最大的特点就是知识网格的特性。
Knowledge Grid(知识网格)包含了Data Pack Node(知识节点),每个知识节点又对应于一个Data Pack(数据块)。
存储层最底层就是一个个的Data Pack(数据块)。每一个Pack装着某一列的64K个元素,所有数据按照这样的形式打包存储,每一个数据块进行类型相关的压缩(即根据不同数据类型采 用不同的压缩算法),压缩比很高。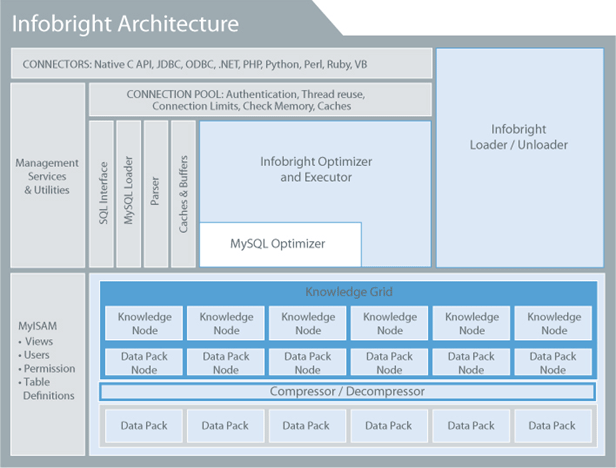
3.4 greenplum
Greenplum是一种基于postgresql的分布式数据库,它也利用了MPP分布式架构。
3.5 dremel
Dremel 是Google 的“交互式”数据分析系统。可以组建成规模上千的集群,处理PB级别的数据。
Dremel的特点:
- 按列存储的嵌套数据格式
- 多级执行查询树
3.6 monetdb
monetdb暂时介绍的太少,没有商用。
四,其他
说了这么多,那么列式数据库的高效到底在哪里?为什么列存储会比行存储更高效呢?我们看看其原理:
4.1 原理
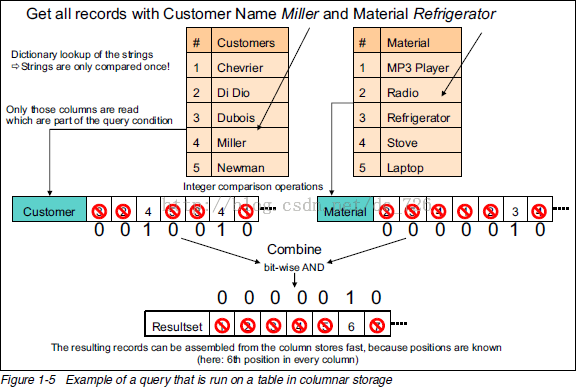
列式查询的原理就是延迟物化,直到最后才把值查出来。
假设我们用的数据字典压缩存储列。如果要查询符合条件的记录,我们可以按照以下方式:
- 去字典表里找到字符串对应数字。
- 用数字去列表里匹配,匹配上的位置设为1。
- 把不同列的匹配结果进行位运算得到符合所有条件的记录下标。
- 使用这个下标组装出最终的结果集。
4.2 特点
列式数据库优点:
- 极高的装载速度(最高可以等于所有硬盘IO的总和,基本是极限了)
- 适合大量的数据而不是小数据
- 实时加载数据仅限于增加(删除和更新需要解压缩Block 然后计算然后重新压缩储存)
- 高效的压缩率,不仅节省储存空间也节省计算内存和CPU。
- 非常适合做聚合操作。
列式数据库缺点:
- 不适合扫描小量数据
- 不适合随机的更新
- 批量更新情况各异,有的优化的比较好的列式数据库(比如Vertica)表现比较好,有些没有针对更新的数据库表现比较差。
- 不适合做含有删除和更新的实时操作。