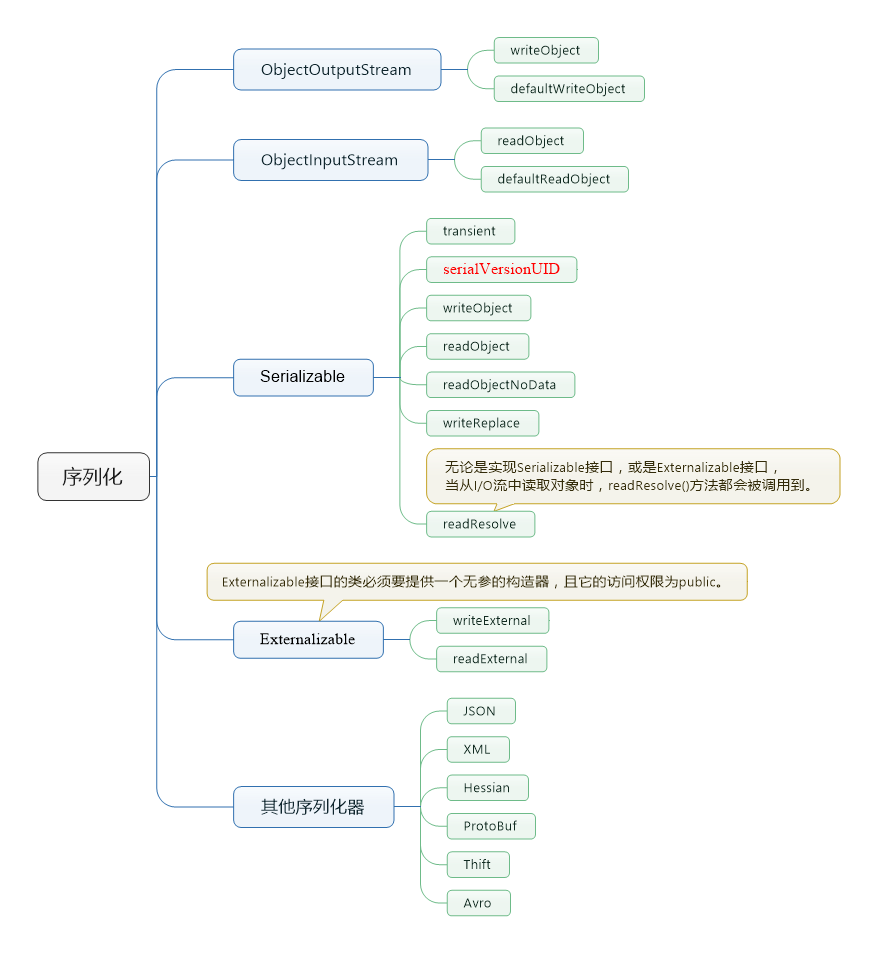
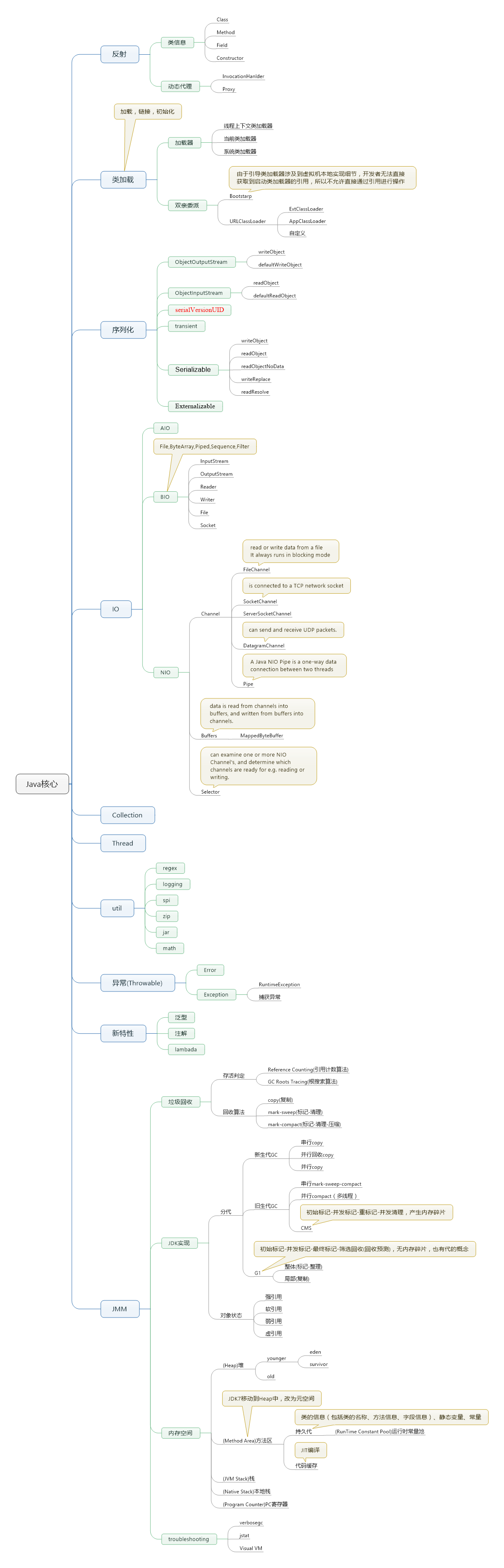
本文主要从整体架构,功能特性,和其他方面介绍集合。
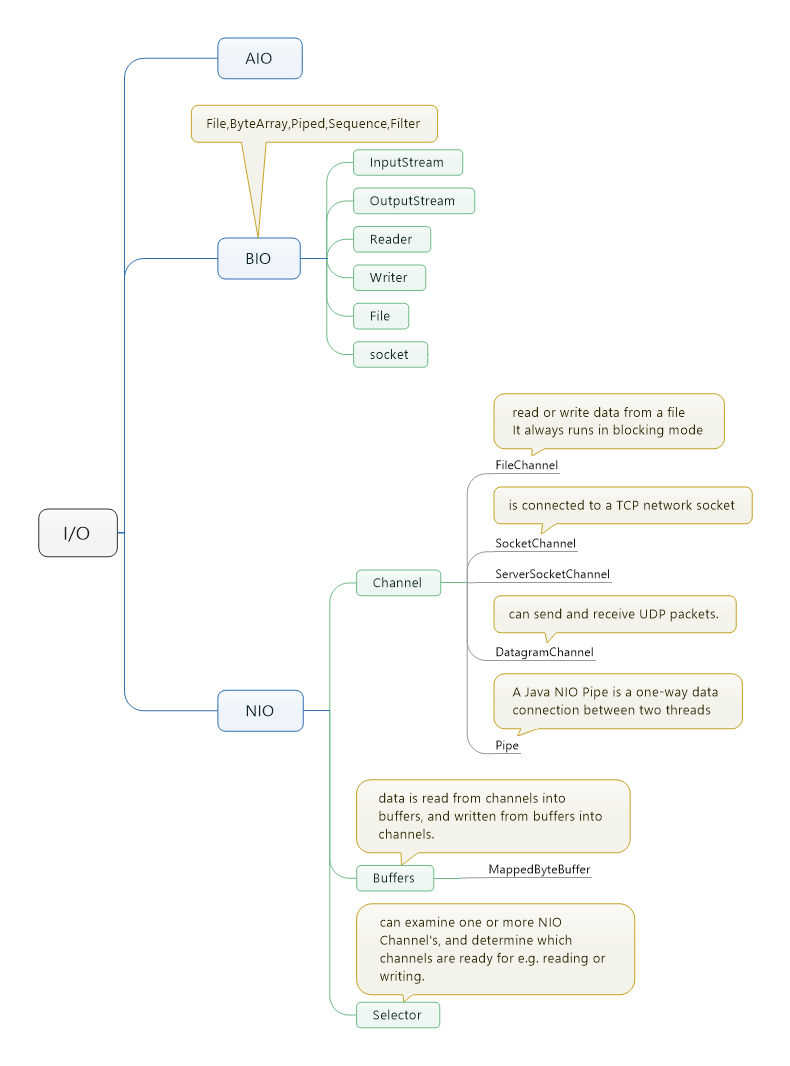
一.整体架构
上图: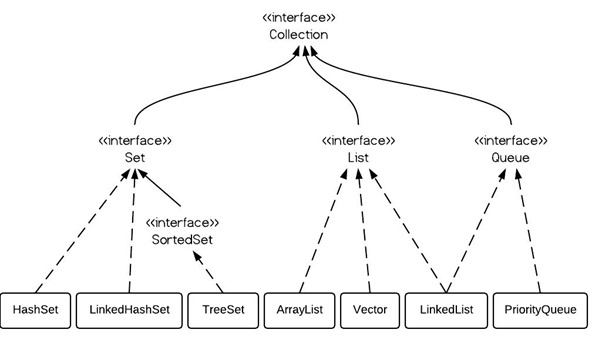
我们可以看到集合主要分为set,list和queue这三类,似乎还有一个Stack。它在哪里呢?
我们看JDK代码:public class Stack<E> extends Vector<E>,原来它继承了Vector。
看上面这个图,我们是不是有点疑问,为什么Linkedlist实现了List又实现了Queue。这是因为List可以模拟Queue的行为,所以也可以将他看成是Queue对象,只需要去掉List的随机访问需求即可,从而实现更高效的并发。
了解了Collection后,我们发现JDK中还有个Collections,它是什么鬼东西?查看源码,我们发现它是包含了对Collection的基本静态方法,例如排序,创建,复制等。同理,Arrays是对数组的操作,Executors是对Executor的操作。有没有一种感觉写jdk的人喜欢用名称加s来代表一个utils。
SET
一个不包括重复元素(包括可变对象)的Collection,是一种无序的集合。Set不包含满 a.equals(b) 的元素对a和b,并且最多有一个null。实现Set的接口有:EnumSet、HashSet、TreeSet等。下图是Set的JDK源码UML图。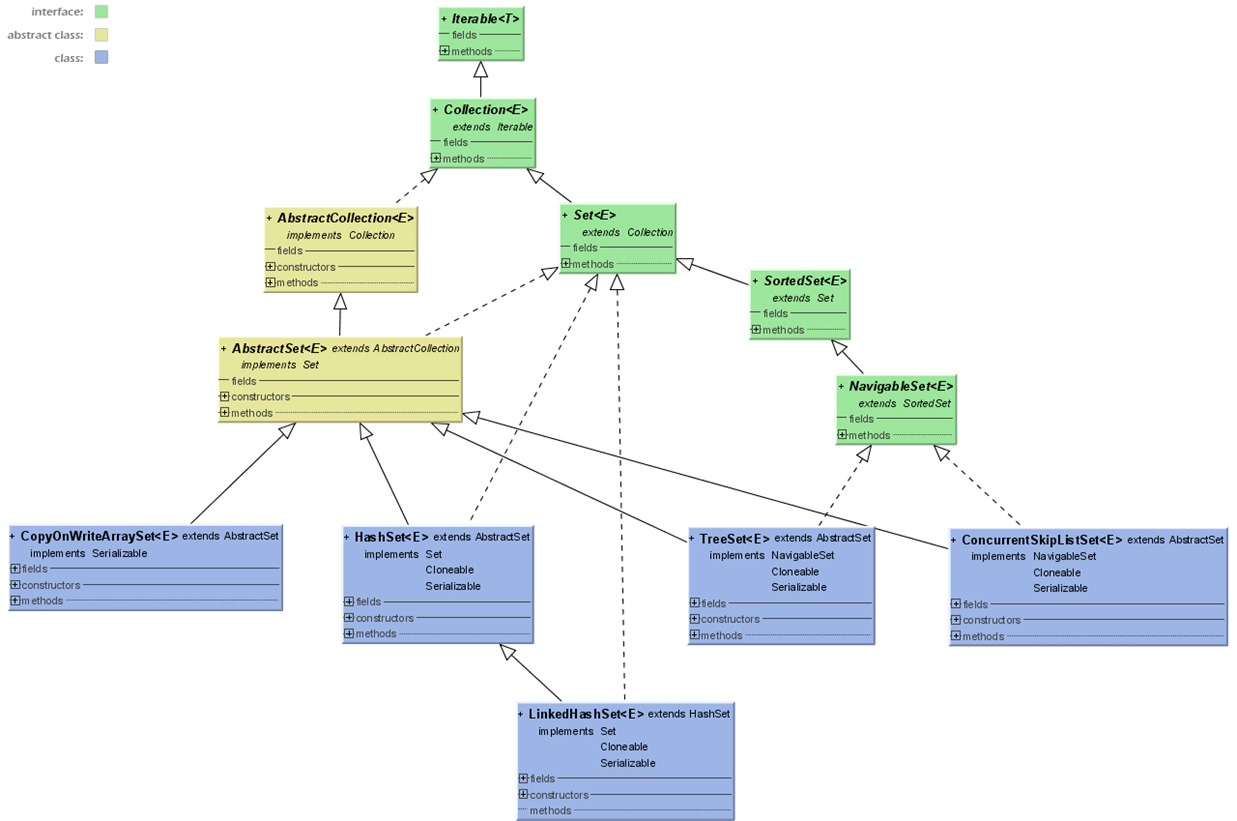
List
一个有序的Collection(也称序列),元素可以重复。确切的讲,列表通常允许满足 e1.equals(e2) 的元素对 e1 和 e2,并且如果列表本身允许 null 元素的话,通常它们允许多个 null 元素。实现List的有:ArrayList、LinkedList、Vector、Stack等。下图是List的JDK源码UML图。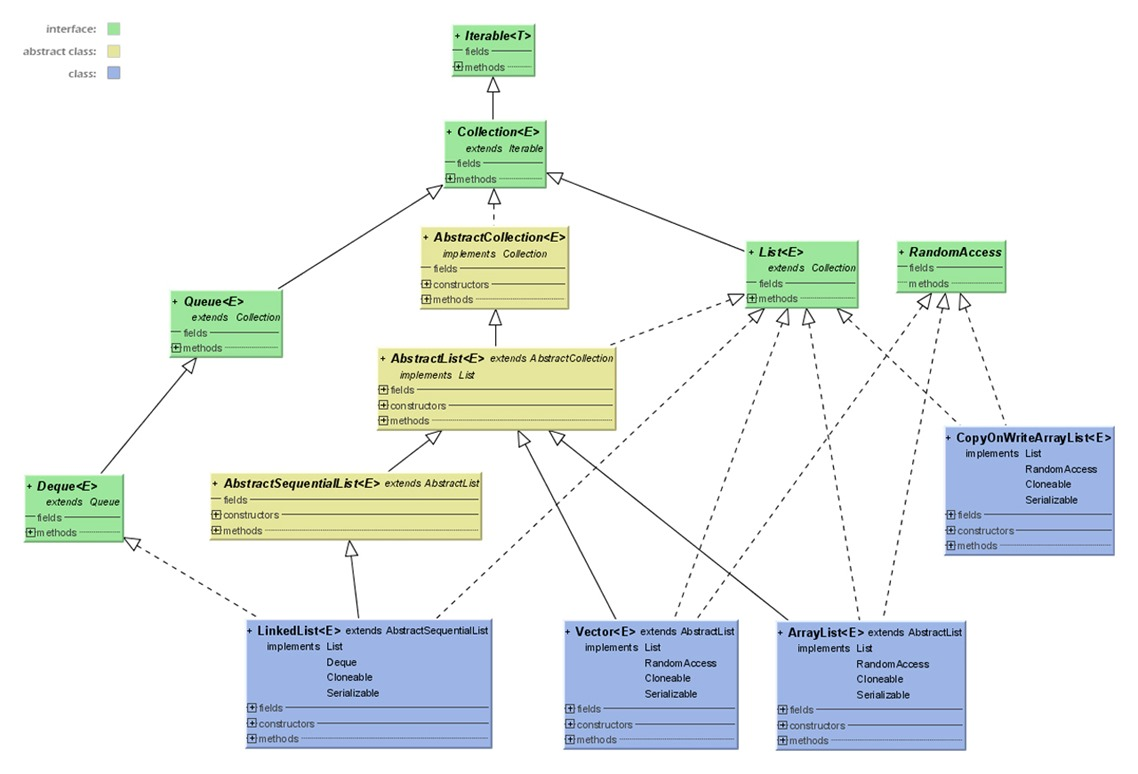
Queue
一种队列则是双端队列,支持在头、尾两端插入和移除元素,主要包括:ArrayDeque、LinkedBlockingDeque、LinkedList。另一种是阻塞式队列,队列满了以后再插入元素则会抛出异常,主要包括ArrayBlockQueue、PriorityBlockingQueue、LinkedBlockingQueue。虽然接口并未定义阻塞方法,但是实现类扩展了此接口。下图是Queue的JDK源码UML图。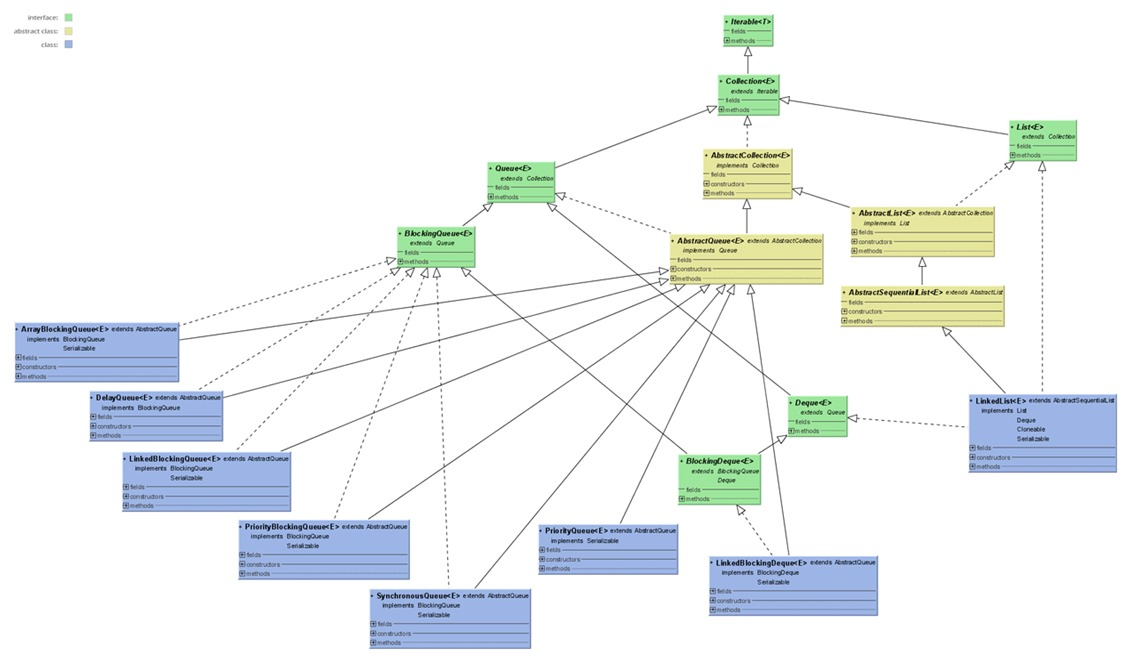
二,功能特性
以下比较基于ArrayList,linkedList,Vector,Stack,HashSet,TreeSet,HashMap,TreeMap
1,添加元素
在添加元素上,ArrayList,Vector的性能相对较差,原因是ArrayList在容量不够时需要扩充。
2,查找元素
在查找元素上,ArrayList,linkedList,Vector,Stack的性能略差一点点,这是由于他们在查找时需要遍历整个集合。而Set,Map类型的都是通过hash后再在链表上查找,因此速度比较快。
3,删除元素
在删除元素上,除了TreeMap和TreeSet外,其他集合类型的性能基本无差异,TreeSet基于TreeMap实现,TreeMap之所以性能相对较差的原因是它在删除时需要排序。
List适用于允许重复元素的单个对象集合场景,Set适用于不允许重复元素的单个对象集合场景,Map适合key-value结构的集合场景。
三,并发结构
1,ConcurrentHashMap
线程安全的haspmap,默认采用16个Segment存储对象。每个Segment一把锁,可允许16个线程同时并发的操作集合对象。
2,CopyOnWriteArrayList
CopyOnWriteArrayList是一个线程安全的,并且在读操作时无需加锁的ArrayList。
3,ArrayBlockingQueue
ArrayBlockingQueue是一个基于数组,先进先出的,线程安全的集合类,其特色为指定时间的阻塞读写,并且容量是可限制的。
offer(E,long,TimeUnit) 插入元素到数组的尾部,如果数组已满,则等待。poll(E,long,TimeUnit)获取数组中的第一个元素,如果数组中没有元素,则等待。
4,LinkedBlockingQueue
LinkedBlockingQueue采用链表的方式存储对象。
对于读操作take和poll,采用一把锁,对于写操作put和poll,采用另一把锁。因此在高并发读写操作多的情况下,性能好于ArrayBlockingQueue。但在遍历和删除元素时,需要2把锁同时锁住。
5,IndentityHashMap
简单说IdentityHashMap与常用的HashMap的区别是:前者比较key时是“引用相等”而后者是“对象相等”,即对于k1和k2,当k1==k2时,IdentityHashMap认为两个key相等,而HashMap只有在k1.equals(k2) == true 时才会认为两个key相等。
6,ConcurrentSkipListMap
SkipList是红黑树的一种简化替代方案,是个流行的有序集合算法。在4线程1.6万数据的条件下,ConcurrentHashMap 存取速度是ConcurrentSkipListMap 的4倍左右。
但ConcurrentSkipListMap有几个ConcurrentHashMap 不能比拟的优点:
- ConcurrentSkipListMap 的key是有序的。
- ConcurrentSkipListMap 支持更高的并发。ConcurrentSkipListMap 的存取时间是log(N),和线程数几乎无关。也就是说在数据量一定的情况下,并发的线程越多,ConcurrentSkipListMap越能体现出他的优势。
四,其他特性
算法
- Colletions.sort(list) 与 Arrays.sort(T[])
Colletions.sort()实际会将list转为数组,然后调用Arrays.sort(),排完了再转回List。
PS. JDK8里,List有自己的sort()方法了,像ArrayList就直接用自己内部的数组来排,而LinkedList, CopyOnWriteArrayList还是要复制出一份数组。
而Arrays.sort(),对原始类型(int[],double[],char[],byte[]),JDK6里用的是快速排序,对于对象类型(Object[]),JDK6则使用归并排序。为什么要用不同的算法呢?
- JDK7的进步
到了JDK7,快速排序升级为双基准快排(双基准快排 vs 三路快排);归并排序升级为归并排序的改进版TimSort,一个JDK的自我进化。
- JDK8的进步
再到了JDK8, 对大集合增加了Arrays.parallelSort()函数,使用fork-Join框架,充分利用多核,对大的集合进行切分然后再归并排序,而在小的连续片段里,依然使用TimSort与DualPivotQuickSort。
五,参考资料
- 《分布式JAVA应用 基础与实践》—-林昊
- JDK78数则
- Java 容器 & 泛型(1):认识容器