上一节我们了解了member的查询过程。下面,我们将进入mdx的执行过程。
首先,我们需要了解3个重要的类,结果集RolapResult,求值上下文RolapEvaluator与单元格读取CellReader。这3个类的关系是首先由在RolapResult初始化构造函数中传入一个Query,由Query生成一个RolapEvaluator,然后由Query中的Calc根据RolapEvaluator来获取轴上的成员。获取到所有的成员之后,RolapEvaluator根据成员调用CellReader获取到当前值。
RolapResult
RolapResult是一个运行中的请求的结果集。
Mondiran的执行结果由RolapResult类表单,由于mdx查询语句本身就包含on rows(行轴上)、on columns(列轴上)和where部分(切片轴上),结果集中相对应的为ROlapAxis对象,这其中有个sliceAxis对象。因此结果集是由若干ROlapAxis对象和一个RolapCell组构成的。每个axis对象又由若干Position对象组成,每个Position对象又可能由若干member组成(注意一个postion会横跨多个维度的成员)。注意ROlapAxis是抽象类,实际的对象类可能随着不同的轴是不同的。如图:
图中,column轴上两个position(每个position含有一个成员),分别是:
[[Measures].[YJD]]
[[Measures].[GCLC]]
Row轴上有三个position(每个position含有二个成员),分别是:
[[dimLX].[All dimLXs], [dimTime].[All dimTimes]]
[[dimLX].[All dimLXs].[宁波—梁辉], [dimTime].[All dimTimes]]
[[dimLX].[All dimLXs].[同江-三亚], [dimTime].[All dimTimes]]
切片轴上则有一个position:
[[dimStation].[All dimStations].[宁波市]]
单元值们则放置在RolapResult中的cellInfos对象里,属CellInfoContainer接口,其中存放着CellInfo,并通过Cellkey进行索引。
CellKey:用于在maps里访问cellinfo时使用的键值,根据cell的位置来决定键值。CellKey共有四个默认实现,及zero、one、two、three和many版的实现,分别对应着轴的个数。这些类中关键的属性便是存储各轴的位置值。
CellInfo、CellInfoContainer:内部类。CellInfo包含了一个cell所需要的所有信息(最关键的包含value值和一些formatter设置);最终将作为构造ROlapCell对象的参数。CellInfoContainer显然是cellInfo的容器,并使用CellKey来索引。
ROlapCell:最终返回给jpivot的cell单元值。
RolapEvaluator
RolapEvaluator即在多维环境中计算表达式。
该类中维护一个很重要的对象,即currentMembers,该上下文对象针对每个维度都包含了一个成员;通过setContext方法用来设置当前维度,以开始计算当前维度组合下的表达式值。
该类有一个方法:public final Object evaluateCurrent()
该方法就是对单元格的求值,在该方法中,规定了solver order的求解顺序。
CellReader
CellReader即单元格读取。
Cells会被求值多次。第一次时, Evaluator使用FastBatchingCellReader来求值。当一个单元被求值时,evaluateCurrent()被调用。此时FastBatchingCellReader并没有被调用,而是为那个cell记录了一个 CellRequest并且return (not throw) an exception。在所有的cells都有了对应的CellRequests之后, Aggregation会生成 SQL,以一个单独的sql请求来载入所有的cells。然后由AggregatingCellReader 重新计算cells,从缓存中返回cells值。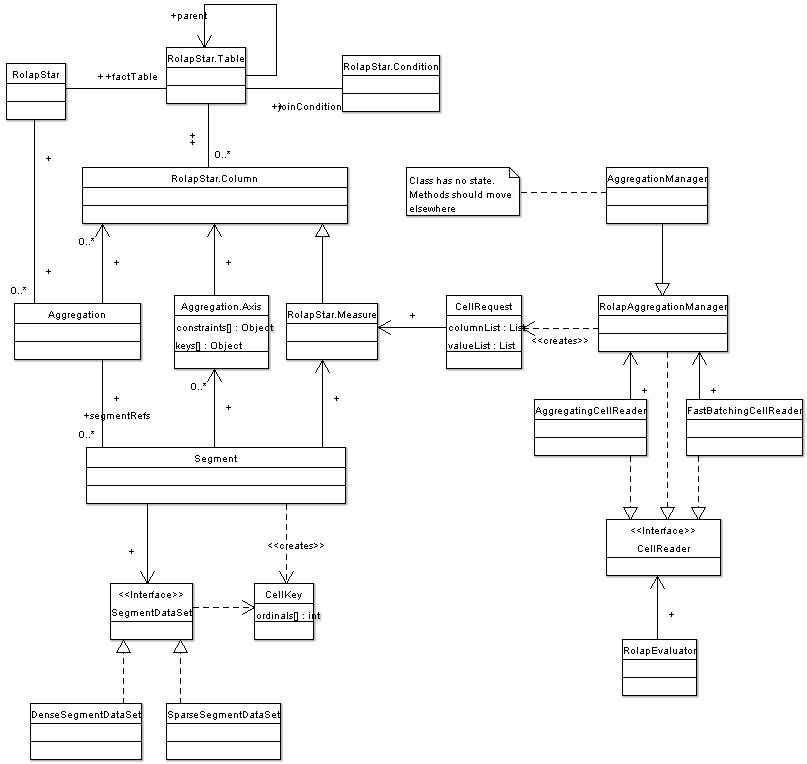
FastBatchingCellReader
主要方法,Object get(Evaluator evaluator)
- 首先根据当前的上下文环境(即一组members)创建cellRequest,cellRequest中包含了所有必要的从star中取值的信息。该组members的交集便是要求值的单元格,其中切片轴上的成员和其他轴上的成员完全同等对待;其中度量轴上的成员要求上StoredMeasure(非计算成员CaculatedMember);度量值上的成员位于第一个。通过调用request的addConstrainedColumn()方法把各member对应的column和value(属StarColumnPredicate)值加至到request中.
- 调用AggregationManager.getCellFromCache(request,pinnedSegments)方法从缓存中获取cell值。首先根据request中的列组索引标识从缓存中获取aggreation缓存对象,如果为空说明缓存还未建立则直接返回null,如果有值则调用aggregation.getCellValue(measure,colValueKeys)方法获取缓存的cell值;getCellValue内部首先会根据measure查找匹配的segment,然后调用segment.getCellValue(keys)从segment的dataset缓存集中查找相应的cell值。
- 如果getCellFromCache返回为null则调用recordCellRequest()记录需求。这些cell request会被组织成多个cell request batch,以便将来聚合层进行批读取以提高效率。关于batch的详细讨论参见下面Batch类章节。
- 上层会在适当的时候调用batchCellReading.loadAggregations()以实际读取这些cell值,前提是batches对象中已有cellRequest了。每个batch的读取参见batch. loadAggregation()方法,最终调用聚合层的方法,参见aggreation.load(….)。
FastBatchingCellReader.Batch类
每个batch对应与一组特定的columns环境下的cell求取(具有相同的列和列值(列值是具体的值,不会是“all”值));从batch的属性可以看出batch包含了哪些上下文:
- RolapStar.Column[],这个指明了基于哪些列(也即基于哪些维度,包括切片维度)进行读取;
- Set
[],保存了每列的限定值,对于一列而言,限定值可能会有多个(毕竟是批处理,一次请求多个); - MeasureList,指明求取哪些度量值上的cell(度量值本质是度量维上的限定值)。
- BitKey,该batch的唯一索引。
如图所示的一个mdx查询结果界面: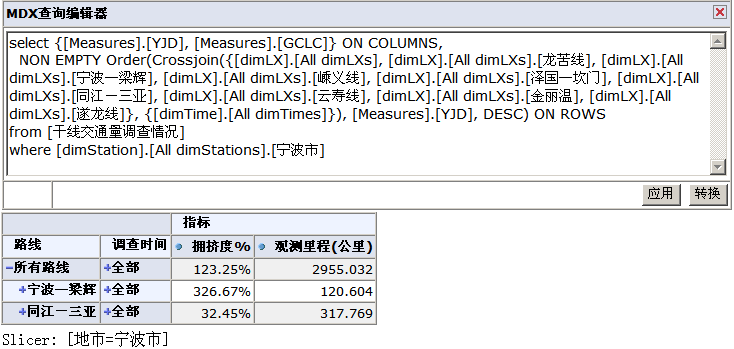
此时会产生两个batch,每个batch最终可能会产生若干segment,segment是cells的集合,
一个batch是(其中“当量数/适应交通量=拥挤度”,拥挤度是计算成员),最终产生3个segment,每个segment只有一个cell:
(地市=’宁波市’,measure=’观察里程’)
(地市=’宁波市’,measure=’当量数’)(地市=’宁波市’,measure=’适应交通量’)
另一个batch是(其中的G310等是路线代码,最终过滤掉空值后就剩下两个了) ,最终产生3个segment,每个segment有多个cell:
(地市=’宁波市’,roadId in (G310,G322,G210,S321….),measure=’观察里程’) (地市=’宁波市’,roadId in (G310,G322,G210,S321….),measure=’当量数’) (地市=’宁波市’,roadId in (G310,G322,G210,S321….),measure=’适应交通量’)
此次:mdx的执行过程就分析完了。
ps:最后这一点来源于网络,由于从文档上无法得知作者来源,如有侵权还望见谅。