包mondrian.rolap.agg,管理聚合缓存,这些缓存中包含着各单元格值。
RolapStar中含有aggregation(聚合),一个aggregation是针对一组columns的,该聚合可以包含多个segment,同一个aggregation中的每个segment都将覆盖到相同的列集合;每个segment表达了一组cell值,这些cell自然是由具体的列值和一个必备度量值(如下面的unit sales)来限定,如:(Unit sales, Gender = 'F', State in {'CA','OR'}, Marital Status = anything),由于其中的列值可能会取多个,因此最终表达的cell值也可能是多个。RolapStar中有一个aggregations,是一个map对象,通过request的constrainedColumnsBitKey来索引一个aggregation。
聚合装载过程
实际中无论是底层的单元值还是聚合后的单元值都是放在聚合对象aggregation中的。以aggregation.load(colums,measures,predicates,pinnedSegments)为入口:
参数中的除了measure不一样外,其限定的列(colums)及列值(prediactes)都是一致的。因此转换成对对若干segment[]的求值: Segment.load(segment[],….),在该方法内部:
- 首先根据segments中的信息生成sql查询语句,有两个不同的生成类:AggQuerySpec和SegmentArrayQuerySpec,前者用于找到聚合表情况下的sql语句生成,后者用于基于原始表的sql语句生成。具体可以参见它们的generateSqlQuery()方法,这里注意对以distinct count有不同的生成方法。Sql生成的核心类是sqlQuery,类似于交换系统中的QuerySqlFactory类。注意:聚合操作如avg、sum等都最终还是利用sql语句实现的,并非mondiran自己实现这些聚合功能。
- 利用jdbc,执行sql语句,获取到jdbc 结果集。参见mondrian.rolap.RolapUtil.executeQuery()方法。
- 解析结果集,将结果集中的数据填充到rows[][]二维数值中,并且把各列的值也填充好。如图:
结果集每条记录的值如宁波市、G010….,前面两个是维度列值,后面几个是度量值。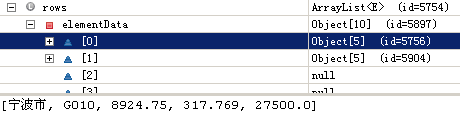
各列的值(其中第0项值为:[宁波市]):
- 决定采用稀疏性(sparse)还是稠密性(dense)SegmentDataSet存储(如果是稠密的,就用数组存储,如果是稀疏的,则用Map存储);并创建该空的DataSet对象。每个segment关联一个DataSet对象;但其稀疏性还是稠密性都是一致的。注意dataset中单元值的个数可能是1个或多个,是由各限定列的指定值个数乘积,若所有限定列都取单值,则显然最终决定一个唯一的单元。
- 将上述的rows中间集转换到SegmentDataSets集中。最后再分拣给每个segment,确保每个segment的setData(SegmentDataSet)被调用。
segment详解
我们看Segment里面都放了什么:
protected final Column[] columns; //约束列
public final MeasureColumn measure;//这个segment是针对哪个度量的。
private RolapModel model; //对模型的引用
public final StarColumnPredicate[] predicates; //Segment存在哪些断言
从这里我们可以看出,Segment就是对某个Cube的断面做的定义。那它的单元值是存在哪里呢?
就是我们在上面讲的到SegmentDataSet,由它来存储单元值。那么如何关联Segment与SegmentDataSet呢?这里我们有要讲到SegmentWithData。我们看他的定义:
public class SegmentWithData extends Segment{
final SegmentAxis[] axes;//一组维度的约束
private final SegmentDataset data;//数据存储
...
//此方法判断SegmentWithData中是否存在以keys为维度的单元值
public Object getCellValue(Object[] keys) {
assert keys.length == axes.length;
int missed = 0;
CellKey cellKey = CellKey.Generator.newCellKey(axes.length);
for (int i = 0; i < keys.length; i++) {
Comparable key = (Comparable) keys[i];
int offset = axes[i].getOffset(key);
if (offset < 0) {
if (axes[i].wouldContain(key)) {
// see whether this segment should contain this value
missed++;
continue;
} else {
// this value should not appear in this segment; we
// should be looking in a different segment
return null;
}
}
cellKey.setAxis(i, offset);
}
if (isExcluded(keys)) {
// this value should not appear in this segment; we
// should be looking in a different segment
return null;
}
if (missed > 0) {
// the value should be in this segment, but isn't, because one
// or more of its keys does have any values
return FunUtil.nullValue;
} else {
//cellkey是对一组维度的值得定义
Object o = data.getObject(cellKey);
if (o == null) {
o = FunUtil.nullValue;
}
return o;
}
}
}
在这里,SegmentWithData包装了Segment与它单元值之间的关系,通过SegmentAxis来判断当前比较的值是否相同。
下图是有两个限定列的两个segment的描述(注:其中roadid列虽然指定了8个候选值,但由于使用了空行/列过滤,最后只剩下两个路线有值,故最后segment结果集的单元数也只有两个,对应于G010和G318的):

其中第二个对应的dataset为:
[317.769, 120.604]
对应的透视界面为(参见其中的“观测里程”度量值,与上面的dataset一致):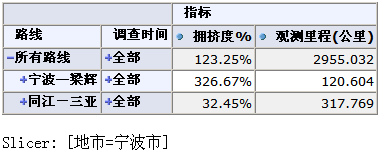
再譬如有三个限定列的segment描述,它们位于另一个aggreation对象中:(其中timeId列的any代表所以可能的时间值,共有2003~2005三个年,所以最终该segment共有3个cell值)
对应的dataset为:
[129.910, 129.909, 57.950]
对应的透视界面为(显然该aggreation还有另外一个segment,其中的roadId对应于G010—宁波梁辉):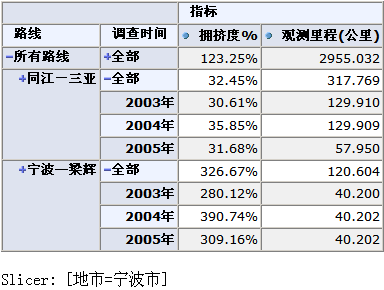
再譬如维度中有多个层次的情况时,一个维度会对应多个列:
Query query = connection.parseQuery(
"SELECT" +
" {[Time].[1997]," +
" [Time].[1997].Children} ON COLUMNS," +
" {[Customer].[USA]," +
" [Customer].[USA].[OR]," +
" [Customer].[USA].[WA]} ON ROWS" +
"FROM [Sales]");
Result result = connection.execute(query);
该语句执行后产生的segment分别为(除了第一个外,其他segment都会包含多个cell,因为它们的限定列中含有多值的情况):
Segment YN#1 Year Nation Unit Sales
1997 USA xxx
Predicates: Year=1997, Nation=USA
Segment YNS#1 Year Nation State Unit Sales
1997 USA OR xxx
1997 USA WA xxx
Predicates: Year=1997, Nation=USA, State={OR, WA}
Segment YQN#1 Year Quarter Nation Unit Sales
1997 Q1 USA xxx
1997 Q2 USA xxx
Predicates: Year=1997, Quarter=any, Nation=USA
Segment YQNS#1 Year Quarter Nation State Unit Sales
1997 Q1 USA OR xxx
1997 Q1 USA WA xxx
1997 Q2 USA OR xxx
1997 Q2 USA WA xxx
Predicates: Year=1997, Quarter=any, Nation=USA, State={OR, WA}