特点
MongoDB是它是一个面向集合的,模式自由的文档型数据库。那么什么是文档性数据库呢?它与其他的数据库的差别在哪里?
面向集合的存储( Collenction-Orented):适合存储对象及JSON形式的数据。
意思是数据被分组存储在数据集中, 被称为一个集合( Collenction)。每个集合在数据库中都有一个唯一的标识名 ,并且可以包含无限数目的文档 。集合的概念类似关系型数据库( RDBMS)里的表( table), 不同的是它不需要定义任何模式( schema)。
模式自由(( schema-free)
意味着对于存储在 MongoDB 数据库中的文件,我们不需要知道它的任何结构定义。提了这么多次”无模式”或”模式自由 “,它到是个什么概念呢?例如,下面两个记录可以存在于同一个集合里面:
{“welcome” : “Beijing”}
{“age” : 25}文档型
意思是我们存储的数据是键-值对的集合,键是字符串,值可以是数据类型集合里的任意类型,包括数组和文档 . 我们把这个数据格式称作 “ BSON ” 即 “ Binary Serialized dOcument Notation.”
适用场景
网站数据: MongoDB 非常适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性
缓存:由于性能很高, MongoDB 也适合作为信息基础设施的缓存层。在系统重启之后,由 MongoDB 搭建的持久化缓存层可以避免下层的数据源过载
大尺寸,低价值的数据:使用传统的关系型数据库存储一些数据时可能会比较昂贵,在此之前,很多时候程序员往往会选择传统的文件进行存储
高伸缩性的场景: MongoDB 非常适合由数十或数百台服务器组成的数据库。 MongoDB的路线图中已经包含对 MapReduce 引擎的内置支持
用于对象及 JSON 数据的存储: MongoDB 的 BSON 数据格式非常适合文档化格式的存储及查询
数据逻辑结构
MongoDB 的文档( document), 相当于关系数据库中的一行记录。
多个文档组成一个集合( collection), 相当于关系数据库的表。
多个集合( collection), 逻辑上组织在一起,就是数据库( database)。
一个 MongoDB 实例支持多个数据库( database)。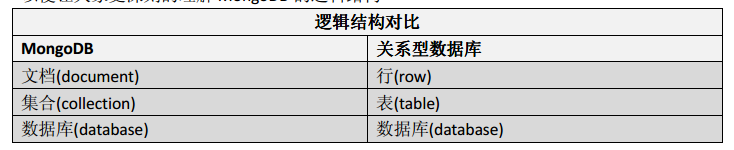
文档(document)、集合(collection)、数据库(database)的层次结构如下图: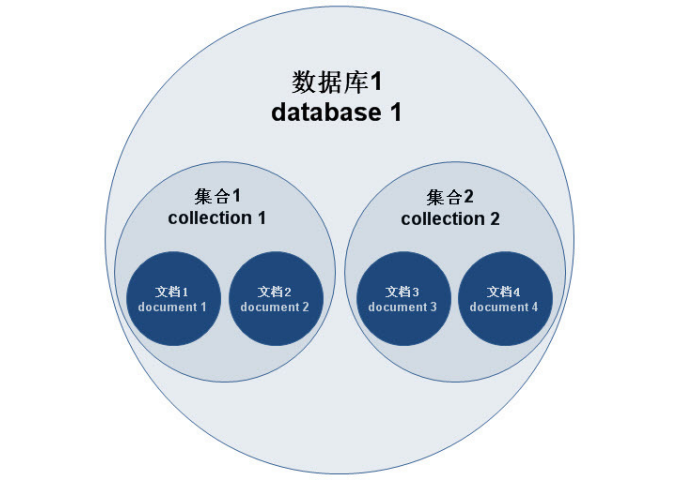
性能篇
MongoDB 提供了多样性的索引支持,索引信息被保存在 system.indexes 中,且默认总是为_id
创建索引 ,它的索引使用基本和 MySQL 等关系型数据库一样。
基础索引
在字段 age 上创建索引, 1(升序);-1(降序)
db.t3.ensureIndex({age:1})
文档索引
db.factories.insert( { name: "wwl", addr: { city: "Beijing", state: "BJ" } } );
db.factories.ensureIndex( { addr : 1 } );
//下面这个查询将会用到我们刚刚建立的索引
db.factories.find( { addr: { city: "Beijing", state: "BJ" } } );
//但是下面这个查询将不会用到索引,因为查询的顺序跟索引建立的顺序不一样
db.factories.find( { addr: { state: "BJ" , city: "Beijing"} } );
组合索引
db.factories.ensureIndex( { "addr.city" : 1, "addr.state" : 1 } );
// 下面的查询都用到了这个索引
db.factories.find( { "addr.city" : "Beijing", "addr.state" : "BJ" } );
db.factories.find( { "addr.city" : "Beijing" } );
db.factories.find().sort( { "addr.city" : 1, "addr.state" : 1 } );
db.factories.find().sort( { "addr.city" : 1 } )
架构篇
MongoDB 支持在多个机器中通过异步复制达到故障转移和实现冗余。多机器中同一时刻只有一台是用于写操作。正是由于这个情况,为 MongoDB 提供了数据一致性的保障。担当Primary 角色的机器能把读操作分发给 slave。
复制集
MongoDB 高可用可用分两种:
Master-Slave 主从复制:
只需要在某一个服务启动时加上–master 参数,而另一个服务加上–slave 与–source 参数,即可实现同步。 MongoDB 的最新版本已不再推荐此方案。
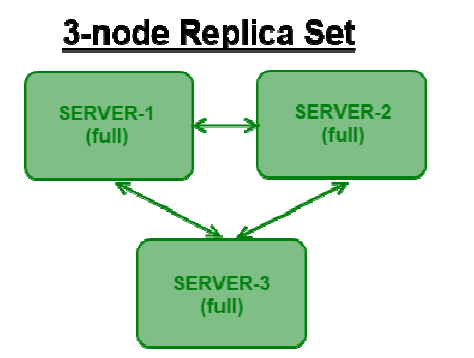
Replica Sets 复制集:
MongoDB 在 1.6 版本对开发了新功能 replica set,这比之前的 replication 功能要强大一些,增加了故障自动切换和自动修复成员节点,各个 DB 之间数据完全一致,大大降低了维护成功。 auto shard 已经明确说明不支持 replication paris,建议使用 replica set, replica set故障切换完全自动。
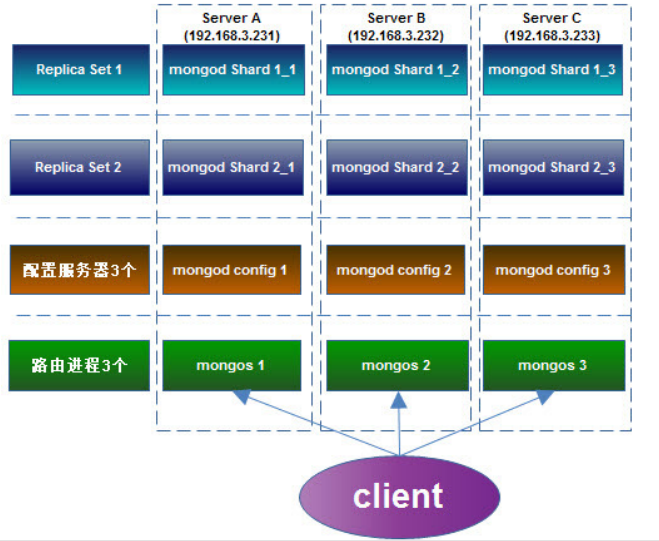
Sharding 分片
这是一种将海量的数据水平扩展的数据库集群系统,数据分表存储在 sharding 的各个节点上,使用者通过简单的配置就可以很方便地构建一个分布式 MongoDB 集群。
要构建一个 MongoDB Sharding Cluster,需要三种角色:
Shard Server
即存储实际数据的分片,每个 Shard 可以是一个 mongod 实例,也可以是一组 mongod 实例构成的 Replica Set。为了实现每个 Shard 内部的 auto-failover, MongoDB 官方建议每个 Shard为一组 Replica Set。
Config Server
为了将一个特定的 collection 存储在多个 shard 中,需要为该 collection 指定一个shard key,例如{age: 1} ,shard key 可以决定该条记录属于哪个 chunk。 Config Servers 就是用来存储:所有 shard 节点的配置信息、每个 chunk 的 shard key 范围、 chunk 在各 shard 的分布情况、该集群中所有 DB 和 collection 的 sharding 配置信息。
Route Process
这是一个前端路由,客户端由此接入,然后询问 Config Servers 需要到哪个 Shard 上查询或保存记录,再连接相应的 Shard 进行操作,最后将结果返回给客户端。客户端只需要将原本发给 mongod 的查询或更新请求原封不动地发给 Routing Process,而不必关心所操作的记录存储在哪个 Shard 上。
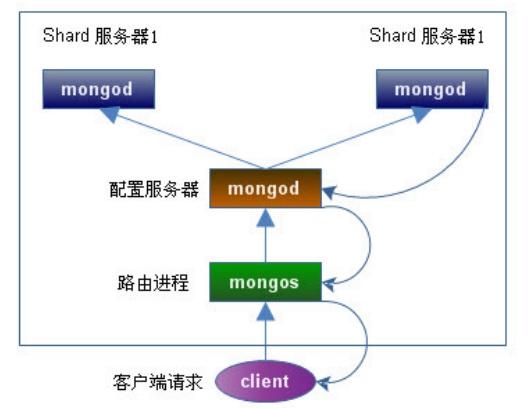
Replica Sets + Sharding
MongoDB Auto-Sharding 解决了海量存储和动态扩容的问题,但离实际生产环境所需的高可
靠、高可用还有些距离,所以有了 ” Replica Sets + Sharding”的解决方案:
Shard:
使用 Replica Sets,确保每个数据节点都具有备份、自动容错转移、自动恢复能力。
Config:
使用 3 个配置服务器,确保元数据完整性
Route:
使用 3 个路由进程,实现负载平衡,提高客户端接入性能