聚合数据模型
数据模型是认知和操作数据时所用的模型。对于使用数据库的人来说, 数据模型描述了我们如何同数据库中的数据打交道。 它与存储模型不同, 后者描述了数据库内部存储及操作数据的机制。
大家日常所说的“ 数据模型” 一词, 一般指应用程序的特定数据所具备的模型。 开发者可能会指着一张数据库的“ 实体 - 关系图 ”( entity-relationship diagram), 把这个包含客户、 订单、 产品等信息的东西叫做他们的数据模型。然而本书的“ 数据模型” 通常表示数据库组织数据的方式, 它的正式名称是“ 元模型”( metamodel)。
NoSQL 技术与传统的关系型数据库相比, 一个最明显的转变就是抛弃了关系模型。 每种 NoSQL 解决方案的模型都不同, 本书把 NoSQL 生态系统中广泛使用的模型分为四类 :“ 键值”、“ 文档”、“ 列族” 和“ 图”。 前三类数据模型有一个共同特征, 我们称其为“ 面向聚合”( aggregate orientation)。
聚合
关系模型把待存储的信息分隔成元组( 行)。 元组是种受限的数据结构 : 它只能包含一系列的值, 因此不能在元组中嵌套另一个元组, 也不能包含由值或元组所组成的列表。 这种简单的数据结构支撑着关系模型 : 所有操作都必须以元组为目标, 而且其返回值也必须是元组。
面向聚合所用的方式与之不同, 我们通常操作数据时所用的单元, 其结构都比元组集合复杂得多。 如果能够以这种复杂的结构来存放列表或嵌套其他记录结构就好了。大家在后面的章节中将会看到,“键值数据库”、“ 文档数据库”、“ 列族数据库” 都使用这种更为复杂的记录。 然而, 没有公认的术语来称呼这种复杂的记录, 在本书中, 把它叫做“聚合”( aggregate)。
聚合是“ 领域驱动设计”[ Evans] 中的术语。 在领域驱动设计中, 我们想把一组相互关联的对象视为一个整体单元来操作, 而这个单元就叫聚合。 在涉及数据操作与一致性管理时, 更是如此。 一般情况下, 我们通过原子操作( atomic operation) 更新聚合的值, 并且在与数据存储通信时, 也以聚合为单位。 这个定义也非常符合“ 键值数据库”、“ 文档数据库” 和“ 列族数据库” 的工作方式。 因为用聚合为单位来复制和分片显得比较自然, 所以在集群中操作数据库时, 还是使用聚合比较简单一些。 此外,由于程序员经常通过聚合结构来操作数据, 故而采用聚合也能让其工作更为轻松。
关系模型与聚合模型示例
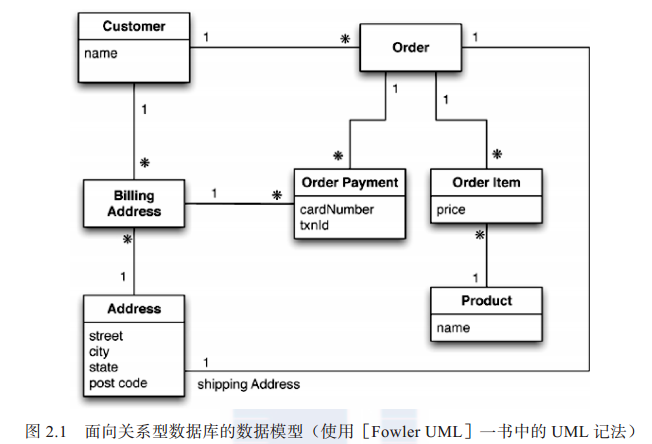
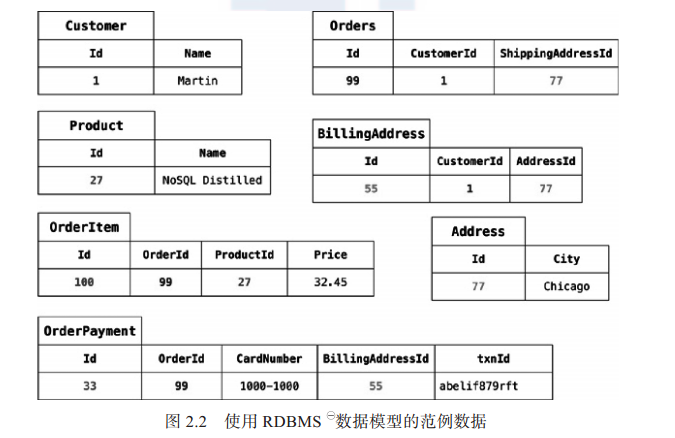
现在我们再来看看, 如果用面向聚合的思路来做, 那么数据模型会是什么样子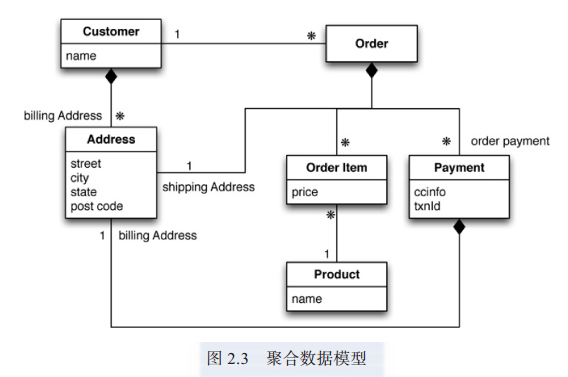
这次也要用一些范例数据, 我们使用 JSON 格式来表示, 因为它是 NoSQL 领域中常用的数据格式。
面向聚合的影响
关系型数据库的数据模型中, 没有“ 聚合” 这一概念, 因此我们称之为“ 聚合无知”( aggregate-ignorant)。 NoSQL 领域中的“ 图数据库” 也是聚合无知的。 这一特征并不是坏事。 聚合的边界一般都很难正确划分出来, 当不同场景要使用同一份数据时,更是如此。
选用面向聚合模型的决定性因素, 就在于它非常适合在集群上运行。 大家应该还记得, 这正是 NoSQL 崛起的杀手锏。在集群上运行时, 我们需要把采集数据时所需的节点数降至最小。如果在数据库中明确包含聚合结构, 那么它就可以根据这一重要信息, 知道哪些数据需要一起操作了, 而且这些数据应该放在同一个节点中。
聚合对于事务处理有一个重要影响。 通常情况下, 面向聚合的数据库确实不支持跨越多个聚合的ACID 事务。 取而代之的是, 它每次只能在一个聚合结构上执行原子操作。 也就是说,如果我们想以原子方式操作多个聚合, 那么就必须自己组织应用程序的代码。
键值数据模型与文档数据模型
键值数据库的聚合不透明 , 只包含一些没有太多意义的大块信息 ; 与此相反, 在文档数据库的聚合中, 可以看到其结构。 不透明的优势在于, 聚合中可以存储任意数据。文档数据库则要限制其中存放的内容, 它定义了其允许的结构与数据类型, 而这样做的好处是, 能够更加灵活地访问数据。
在键值数据库中, 要访问聚合内容, 只能通过键来查找。 而使用文档数据库时,则可以用聚合中的字段查询。 我们可以只获取一部分聚合, 而不用获取全部内容, 此外, 数据库还可以按照聚合内容创建索引 。
列族存储
理解列族模型的最好方式也许就是将其视为两级聚合结构( two-level aggregate
structure)。 与“ 键值存储” 相同,第一个键通常代表行标识符, 可以用它来获取想要的聚合。 列族结构与“ 键值存储” 的区别在于, 其“ 行聚合”( row aggregate) 本身又是一个映射, 其中包含一些更为详细的值。 这些“ 二级值”( second-level value)就叫做“ 列”。 与整体访问某行数据一样, 我们也可以操作特定的列。
列族数据库将列组织为列族。 每一列都必须是某个列族的一部分, 而且访问数据的单元也得是列。 这样设计的前提是, 某个列族中的数据经常需要一起访问。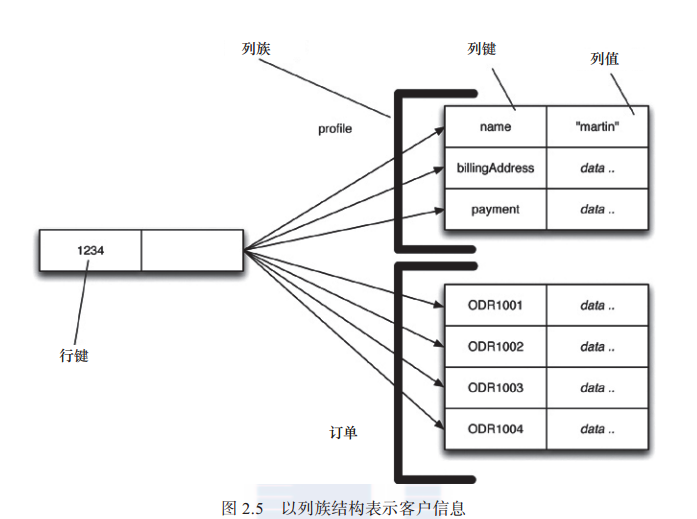
于是, 我们也得出了两种数据组织方式。
- 面向行( row-oriented): 每一行都是一个聚合( 例如 ID 为 1234 的顾客就是一个聚合), 该聚合内部存有一些包含有用数据块( 客户信息、 订单记录) 的列族。
- 面向列( column-oriented): 每个列族都定义了一种记录类型( 例如客户信息),其中每行都表示一条记录 。 你可以将数据库中的大“ 行” 理解为列族中每一个短行记录的串接。
总结
键值数据模型将聚合看作不透明的整体,这意味着只能根据键来查出整个聚合, 而不能仅仅查询或获取其中的一部分。
文档模型的聚合对数据库透明, 于是就可以只查询并获取其中一部分数据了, 不过, 由于文档没有模式, 因此在想优化存储并获取聚合中的部分内容时, 数据库不太好调整文档结构。
列族模型把聚合分为列族, 让数据库将其视为行聚合内的一个数据单元。 此类聚合的结构有某种限制, 但是数据库可利用此种结构的优点来提高其易访问性。