在这一小节中我们主要介绍一些antlr4中的小技巧,这些技巧将极大的扩展antlr4的灵活性。
在不同的通道广播tokens
绝大多数编程语言忽略tokens之间的空格和注释,这意味着他们可以出现在任何地方。对解析器来说,最简单的方式就是跳过他们,什么也不做。
但是如果我们想留下注释可空格的话,应该怎么做呢?
antlr为我们提供了通道,它就像收音机的频道,我们可以指定某些字符发送到不同的频道中。解析器指向正确的通道并且忽略其他的通道。词法规则负责把tokens放到不同的通道中,类CommonTokenStream的职责就是对parser呈现仅仅一个通道。CommonTokenStream保留所有的token序列以至于我们能请求注释在一个特定的token之前或之后。下面的图片呈现了CommonTokenStream的运行过程:
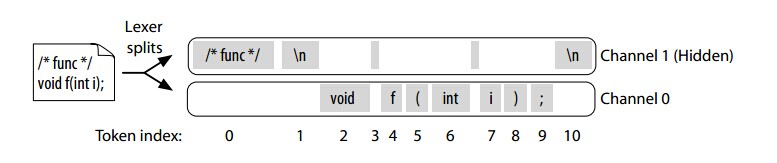
不同的注释可可以发送到不同的通道
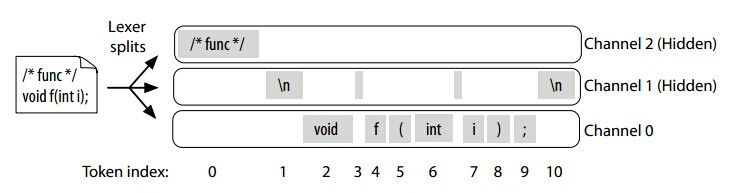
访问隐藏的通道
为了解释如何访问隐藏的通道,我们举个简答的例子。在这里例子中,我们将构建一个解析器将变量后面的注释移到变量前面。
我们最常用的策略是使用TokenStreamRewriter类来重写输入流。下面是一个简单的例子,在类中插入一个序列化id:
ParseTreeWalker walker = new ParseTreeWalker();
InsertSerialIDListener extractor = new InsertSerialIDListener(tokens);
walker.walk(extractor, tree);
public class InsertSerialIDListener extends JavaBaseListener {
TokenStreamRewriter rewriter;
public InsertSerialIDListener(TokenStream tokens) {
rewriter = new TokenStreamRewriter(tokens);
}
@Override
public void enterClassBody(JavaParser.ClassBodyContext ctx) {
String field = "\n\tpublic static final long serialVersionUID = 1L;";
rewriter.insertAfter(ctx.start, field);
}
}
回到最开始,我们看看如何使用隐藏的通道。
public static class CommentShifter extends CymbolBaseListener {
BufferedTokenStream tokens;
TokenStreamRewriter rewriter;
public CommentShifter(BufferedTokenStream tokens) {
this.tokens = tokens;
rewriter = new TokenStreamRewriter(tokens);
}
@Override
public void exitVarDecl(CymbolParser.VarDeclContext ctx) {
Token semi = ctx.getStop();
int i = semi.getTokenIndex();
List<Token> cmtChannel =
tokens.getHiddenTokensToRight(i, CymbolLexer.COMMENTS);
if ( cmtChannel!=null ) {
Token cmt = cmtChannel.get(0);
if ( cmt!=null ) {
String txt = cmt.getText().substring(2);
String newCmt = "/* " + txt.trim() + " */\n";
rewriter.insertBefore(ctx.start, newCmt);
rewriter.replace(cmt, "\n");
}
}
}
}
ANTLRInputStream input = new ANTLRInputStream(is);
CymbolLexer lexer = new CymbolLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
CymbolParser parser = new CymbolParser(tokens);
RuleContext tree = parser.file();
ParseTreeWalker walker = new ParseTreeWalker();
CommentShifter shifter = new CommentShifter(tokens);
walker.walk(shifter, tree);
lexmagic/t.cym
int n = 0;
int i = 9;
we want to generate the following output:
int n = 0;
int i = 9;
所有的工作都发送在exitVarDecl()中。首先,我们得到‘;’所在的位置。然后我们查询它的后面是否有隐藏的通道,如果有的话,我们将获取通道的第一个字符来判断通道中是否有tokens,最后插入到最前面即可。
上下文敏感的词法
在流中孤立
这里需要注意一点,.*?表示非贪婪操作符。他们一直扫描直到遇到符合下一个规则的操作符为止。
COMMENT : '' -> skip ;
CDATA : '<![CDATA[' .*? ']]>' ;
TAG : '<' .*? '>' ; // must come after other tag-like structures
ENTITY : '&' .*? ';' ;
TEXT : ~[<&]+ ; // any sequence of chars except < and & chars
在某种场景下,一个语言可能有几种不同的模式。词法模式可以允许我们分离单个的词法语言到多个子规则。当进入到当前规则的模式时,词法仅仅返回符合的token。最常用的需求可能是在不同的词法之间进行转换。 例如,对于一个xml文件,我们可以定义2个模式,在标签‘<’之外的模式和在‘>’之内的模式。这2中模式是孤立的,下面是这个例子的语法:
lexer grammar ModeTagsLexer;
OPEN : '<' -> mode(ISLAND) ;
TEXT : ~'<' + ;
mode ISLAND;
CLOSE : '>' -> mode(DEFAULT_MODE) ;
SLASH : '/' ;
ID : [a-zA-Z]+ ;
parser grammar ModeTagsParser;
options { tokenVocab=ModeTagsLexer; }
file: (tag | TEXT)* ;
tag : '<' ID '>'
| '<' '/' ID '>'
;
在这个例子中,仅仅是options tokenVocab不常用的。它的意思是保持lexer和parser是同步的,即有相同的token类型。
解析xml
在这个例子中,我们只需要了解有pushMode和popMode即可,就像入栈和出栈一样,挺简单的。
lexer grammar XMLLexer;
COMMENT : '<!--' .*? '-->' ;
CDATA : '<![CDATA[' .*? ']]>' ;
DTD : '<!' .*? '>' -> skip ;
EntityRef : '&' Name ';' ;
CharRef : '&#' DIGIT+ ';'
| '&#x' HEXDIGIT+ ';'
;
SEA_WS : (' '|'\t'|'\r'? '\n') ;
OPEN : '<' -> pushMode(INSIDE) ;
XMLDeclOpen : '<?xml' S -> pushMode(INSIDE) ;
SPECIAL_OPEN: '<?' Name -> more, pushMode(PROC_INSTR) ;
TEXT : ~[<&]+ ;
mode INSIDE;
CLOSE : '>' -> popMode ;
SPECIAL_CLOSE: '?>' -> popMode ;
SLASH_CLOSE : '/>' -> popMode ;
SLASH : '/' ;
EQUALS : '=' ;
STRING : '"' ~[<"]* '"'
| '\'' ~[<']* '\''
;
Name : NameStartChar NameChar* ;
S : [ \t\r\n] -> skip ;
fragment
HEXDIGIT : [a-fA-F0-9] ;
fragment
DIGIT : [0-9] ;
fragment
NameChar : NameStartChar
| '-' | '.' | DIGIT
| '\u00B7'
| '\u0300'..'\u036F'
| '\u203F'..'\u2040'
;
fragment
NameStartChar
: [:a-zA-Z]
| '\u2070'..'\u218F'
| '\u2C00'..'\u2FEF'
| '\u3001'..'\uD7FF'
| '\uF900'..'\uFDCF'
| '\uFDF0'..'\uFFFD'
;
mode PROC_INSTR;
PI : '?>' -> popMode ;
IGNORE : . -> more ;